
SwaggerHub: A collaborative platform for working on OpenAPI/Swagger specification files, and more
- A world standard for describing REST APIs
- Why OpenAPI is so popular
- Struggling against the complexity of the spec
- Collaborative tools as a solution
- Conclusion
Listen here:



A world standard for describing REST APIs
Smartbear recently announced support for new OpenAPI 3.0 version of the spec in SwaggerHub. The 3.0 version of the OpenAPI spec provides a number of enhancements, such as providing support for callbacks, linking between operations, more robust properties with examples, and easier content re-use. You can read about OpenAPI’s 3.0 features here.
(Note: Before continuing, I want to clarify a few terms for those who may be unfamiliar with the OpenAPI/Swagger landscape. “Smartbear” is the company that maintains and develops the open source Swagger tooling (Swagger Editor, Swagger UI, Swagger Codegen, and others). Smartbear formed the “OpenAPI Initiative” and leads the evolution of the “OpenAPI specification”. “SwaggerHub” was developed by Smartbear as a way for teams to collaborate around the OpenAPI specification file. “Swagger” was the original name of the spec, but it was changed to “OpenAPI” to reinforce the open, non-proprietary nature of the standard. People often refer to both names interchangeably, but “OpenAPI” is the preferred term. The Swagger YAML file that you create to describe your API is called either the “OpenAPI specification file” or the “OpenAPI contract.” Now that I’ve cleared up those terms, let’s continue.)
I’ve written in the past about how Swagger-related posts are the most visited posts on my site. The OpenAPI/Swagger specification (instead of RAML or API Blueprint) continues to be the most dominant specification for describing REST APIs. In a recent webinar description about the OpenAPI 3.0 spec, Smartbear says OpenAPI “has emerged as the world’s standard for defining and describing RESTful APIs” — it would be hard to argue otherwise. Because of this emergence as the world standard, in my API course, I added a tutorial on OpenAPI/Swagger and another tutorial on Managing OpenAPI/Swagger Projects with SwaggerHub.
Why OpenAPI is so popular
What accounts for OpenAPI’s popularity and wide acceptance? I think the OpenAPI spec continues to be popular because it provides a standard in an area of technology that is a wild west of differing options, approaches, and terminology. Many technical writers who want to learn more about API documentation are overwhelmed by the breadth and diversity in this space.
The challenge is not so much that there are new terms, new tools, and new documentation techniques to learn. The challenge is that there are so many conflicting terms, competing tools, and varying documentation techniques that unless you’re a maven with APIs, it’s hard to know the right path to follow.
For example, what do you call all of your endpoints/methods/objects/resources/paths? How do you refer to the various types of path/query/body/head parameters? What template or pattern or arrangement do you follow in your API documentation to cover the various elements in the API reference as opposed to other non-reference API topics? Do you auto-generate the spec file from the code, or do you create the spec file manually? Do developers write the content, or do technical writers, or both? Where do you publish your API docs, and how do you integrate the information into your user guides and other help material?
Documenting an API is like being dropped off in a busy, bustling city in another continent, without a map or idea of transportation, and without a clear idea of where you even need to go, just that you need to go somewhere, and do something. It can be overwhelming, because not only is the approach you should take in your documentation unclear, the developer-based nature of the content is often complex as well.
When you discover the OpenAPI specification for describing REST APIs, you suddenly have a map and a direction. You have a language to describe it all. You have a documentation template to populate. You have an idea of what developers want, and you’re inspired with confidence by the positive reception most developers have with Swagger UI’s output. It’s a win all around — the spec grounds technical writers with direction and a map for success in an area rife with confusion and complexity. It’s no wonder the OpenAPI spec is so popular.
Struggling against the complexity of the spec
If the OpenAPI spec were simple and easy to follow, producing documentation would be a no-brainer for both developers and technical writers. But because the API landscape is technically diverse, the OpenAPI spec is technically diverse as well.
Unlike SOAP (a previous protocol for describing web APIs), REST is an architectural style that follows a number of characteristics, not an exact protocol (see What is a REST API?). This architectural style means there’s variety from one API to the next — variety around endpoint operations, parameter types, authorizations used, response formats, and so on.
The OpenAPI spec has to be flexible and robust enough to describe all of this variety. As a result, the OpenAPI spec can be somewhat time-consuming to understand and create, especially if you’re creating it manually.
In a comment thread on Hacker News about OpenAPI’s technical limitations, one developer writes:
It’s crazy to me that it’s harder to write a Swagger file than it is to write the API itself. And there’s a lot of tooling that benefits from Swagger, but… I’ve found they all work 80%. Codegen, documentation, etc get 80% of the way there.
Another person in the Hacker News post comments:
I’ve implemented Swagger with several APIs and agree that it’s crazy complex and time-consuming to write Swagger files manually.
I believe the best use-case for Swagger is to develop the API (perhaps just defining the routes with payload and response, but without controllers), and then auto-generating the Swagger files. This way the API consumers always have an up-to-date documentation, and there is only one place which represents the current state of the API.
A lot of the commenters in the thread debate whether it’s easier to auto-generate the OpenAPI specification file from comments in the code or to write the spec file manually. Although auto-generation is easier, Smartbear says there are more advantages to creating the specification file manually (it acts as a contract or blueprint for developers), and manual creation is the predominant and recommended way that most development shops use Swagger.
Here’s another comment:
I had these same issues. It took me considerably more time and effort to write a Swagger spec and get the UI to actually behave than it did to write my entire API and some simple docs in markdown.
I also tried out the “codegen” and a few other projects that generate boilerplate from a spec (for Python) - the code it generated was frustrating, lengthy, and much more complex than the simple endpoints that I quickly wrote from scratch.
Keywords that stand out here are “harder to write,” “crazy complex and time-consuming,” and “considerably more time and effort.”
Remember this is Hacker News, so most commenters are developers. Granted, not all of them share the same thoughts about the complexity of the spec. One commenter says, “Swagger yaml is hard to write? Hmm… relative to the code that services it or consumes it, I find its pretty trivial.” (Of course, a developer has to say something is trivial that others find complex.)
Overall, creating the OpenAPI spec is not a simple undertaking (especially if your API is complicated), and even many developers find it a difficult task. And yet, I don’t see how the OpenAPI spec could somehow be any less complex than the complexity it describes.
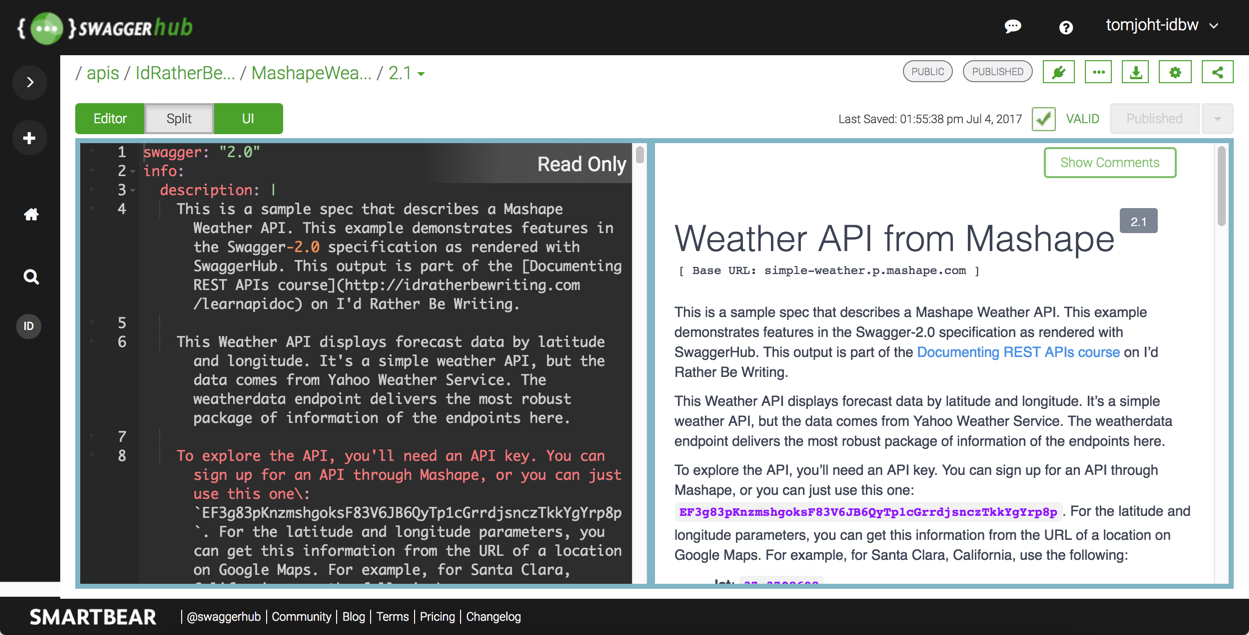
To get a sense of the OpenAPI YAML referenced here, take a look at the sample OpenAPI spec file in my API course. This spec file describes a simple Weather API that I document in my API course.
The sample spec has various objects, such as info, paths, securityDefinitions, and so on. Each object has certain properties you can use to describe it. For example, a paths object contains the endpoints (such as /aqi). Each endpoint contains the operations allowed (such as get or post). Each operation contains properties such as summary, parameters, and responses. To begin a new level in YAML, you add a colon (:), break to a new line, and indent two spaces. This is the equivalent of an object in JSON.
The OpenAPI spec will take some time to learn, and you’ll need to focus in on what’s relevant for your API. (This is particularly true with the securityDefinitions, because the authorization method tends to vary the most across APIs.) But you can learn the spec (just not in five minutes). Compared to learning programming or a syntax like DITA, the OpenAPI is much, much easier.
After a few projects, the syntax and format will become familiar and comfortable to work in. Further, after creating your first OpenAPI specification file, you’ve already got sample code for the type of APIs your company uses, so it’s just a matter of reproducing the same format with new material.
Even so, there is still a learning curve, and this learning curve presents a problem. Many technical writers may quickly decide they don’t have time to sink a few weeks into learning and troubleshooting their OpenAPI specification file. They may punt the task into the developer’s domain for developers to create (or auto-generate) the OpenAPI specification file, and then offer only to edit the content.
I’m not a fan of delegating the API documentation work to developers, as this usually presents technical writers as language editors only and reinforces their technical inadequacy. It puts technical writers in the backseat and lets developers drive. Instead, I prefer to get more involved in guiding and directing the efforts in creating the OpenAPI specification file.
What’s one possible solution to overcoming the technical hurdles around OpenAPI? This is where SwaggerHub comes into play.
Collaborative tools as a solution
SwaggerHub provides a collaboration point for technical writers and developers to interact together on the OpenAPI specification file. As a cloud-based solution, SwaggerHub gives you a secure, online space where both you and developers can log in and interact with a rich-featured editor to create the OpenAPI specification file.
For teams that require on-premise installation, SwaggerHub also offers the ability to install and host behind your company’s firewall in its Enterprise offering.
SwaggerHub also lets you generate various outputs for interactive documentation (including plain HTML for importing into another system), along with implementation code (client SDKs) in nearly every programming language.
Working together with developers in the same space, you can compensate for any gaps in understanding. For example, if technical writers are more familiar with the OpenAPI spec, they can create the bare-bones structure, listing out the endpoints and parameters, and then ask developers to fill in details around the content, following the pattern the tech writer has outlined. Developers respond extremely well to forms and wizards when creating documentation. (The blank page can be terrifying.)
Conversely, if a developer is more familiar with the elements and syntax of the OpenAPI spec, he or she can create the skeleton outline, and the technical writer can fill in the content details and other information.
Either way, technical writers and developers can guide each other through the documentation process. This is what I feel is SwaggerHub’s greatest strength — it enables collaboration between technical writers and developers, letting them work together on creating and fine-tuning the specification file.
With SwaggerHub, you aren’t emailing files back and forth. You don’t need to create and merge branches in git (though, you can source the file from Github if you want). You don’t need to try to use Google Docs or Dropbox to collaborate. In fact, SwaggerHub even allows you to add comments in the margins of the spec, so when a developer provides a jargon-filled description of something, you can highlight it and ask, “What do you mean here — can you be more specific?”
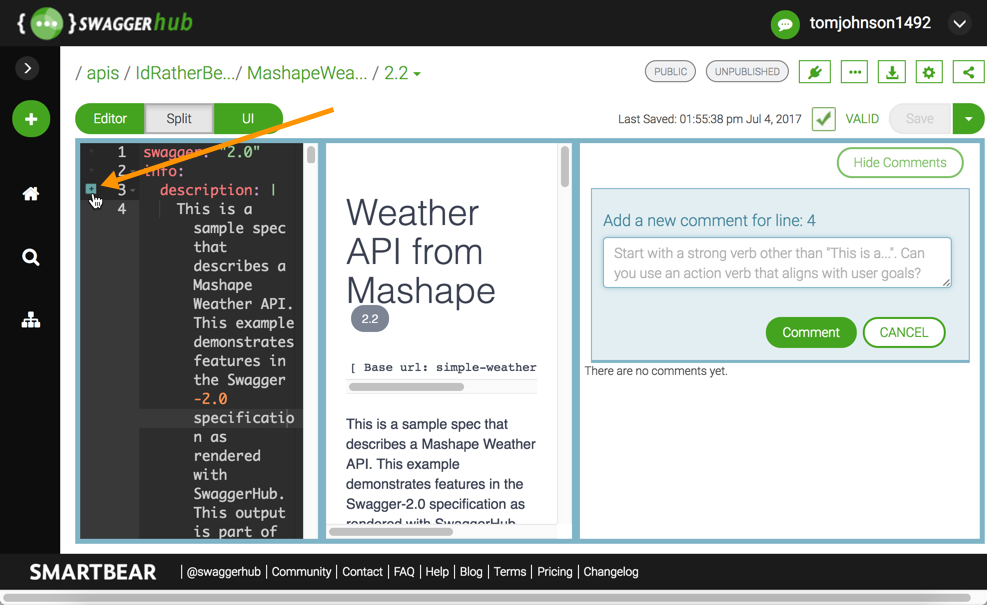
Collaboration is just one aspect of SwaggerHub, of course. In my tutorial on how to Manage OpenAPI Projects with SwaggerHub, I cover a number of other SwaggerHub features including the following:
- The Swagger Editor
- Version support
- Inline commenting/review
- Auto-generation of client SDKs
- HTML export
- Mocking servers
- Content re-use (domains)
- Organizations and projects
See my tutorial Manage OpenAPI/Swagger Projects with SwaggerHub to learn more.
Conclusion
In this post, I argued the following:
- The OpenAPI specification has emerged as the standard for describing REST APIs.
- Creating the OpenAPI spec file (especially manually) can be a complex undertaking.
- SwaggerHub is a tool that can simplify the task of creating the spec file by enabling collaboration between tech writers and developers. SwaggerHub also offers other features to make authoring and publishing easier.
To learn more about SwaggerHub, see https://swaggerhub.com/.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.