

PDF and eBook formats available for API doc course
You can download them here: PDF and eBook formats. Like the rest of my API doc course, these formats are free.
I’ve actually worked on these alternative formats on and off again for a couple of years, but I was always hesitant to make them available because they’re a snapshot in time. Once someone loads an ebook onto a Kindle, are they really going to update it with a later version? Or once someone starts marking up a PDF, or printing it out, they’re unlikely to get a later version of the content.
That said, most people are eager to learn and so want to annotate, highlight, or otherwise mark-up the content, and you can’t do that so easily with web pages. I want to support those learning behaviors and modes.
Also, I’m somewhat mixed about the length of the content. Usually, a book is only several hundred pages, not 900. I recently saw a post on the technicalwriting subreddit with the following question:
Has anyone here completed the idratherbewriting API writing course by Tom Johnson? I’ve been going through the material on his page for three months, but have only gotten through a quarter of the course. I’m learning a lot; however, I’m wondering how long it’s supposed to take for an average person to finish the material.
How long did it you guys to complete the material?
I didn’t set out to create an eternal course that no one can finish — it’s just a space that I’ve been adding to over the years, not too unlike a developer portal, which is also a collection of documents. I plan to break up the content into 5-6 separate guides, which will help people get through the content in a more practical way. But I also want the separated guides to interact together online — kind of like how a developer portal weaves together docs for a variety of related products.
In contrast to standalone docs, with developer portals, there’s more dynamics at play with information flows, cross-references, standard patterns across multiple doc sets, user journeys, and more. Developer portals are much more interesting than a single user guide. I’m still working on the code logic to separate them out, though, so stay tuned.
One challenge with dividing up the content is cross-references. If I generate a PDF that has references to non-printed pages, those references will be broken. I like to link the pages from one section to another in as many ways as makes sense, especially because users rarely start from the first page and proceed linearly. If someone lands on page 297, I want them to be aware of more information related to the content they’re reading.
Links in HTML are easy to create, but with PDFs, converting them to cross-references isn’t so easy. I had to be consistent about my linking strategy. For links to course pages, I used relative links. For links to external pages (even pages not included in the course, such as my contact page), I used absolute links. Then in the stylesheet, I used this logic:
a[href]::after {
content: " (p. " target-counter(attr(href), page) ")"
}
a[href^="http:"]::after, a[href^="https:"]::after {
content: " (" attr(href) ") ";
}
The first style (for relative links) prints a cross-reference (page number) in parentheses after the link, while the second style (for absolute links) prints the web address in parentheses after the link.
I’m using Prince XML to generate PDF from HTML, and the code above shows the functions Prince uses to generate cross-references. There’s some other styling I’ve set up in the stylesheet, but sometimes it’s hit or miss to troubleshoot display issues. Unlike a web page, where you can inspect an element and view the source, with PDF, there’s no equivalent inspector (as far as I know). You have to look at the styles used on the HTML page from which the PDF was generated, and then tweak those styles and regenerate the PDF to see the change. With the Kindle/EPUB output, eReaders add an extra underline to external links that would take readers out of the ebook (into a stripped down web browser).
Over the years, a lot of people have asked about how to create PDF from HTML, specifically static site generators, and I should probably document that approach I’m using on my API doc site. I’m mainly creating a printer-friendly HTML output (no sidebar, top navigation, footer, etc.) and then feeding the auto-generated list of pages into Prince to generate the PDF. But it’s not trivial to get things right. For example, Prince doesn’t handle tags such as max-width, and images require absolute paths to an asset on my computer to be valid; page paths too. So there’s a lot of special configuration going on there to generate the output. But Prince is kind of magical in the way it can simply add pages numbers in the cross references.
The Kindle generation is even more intricate, and I dislike that I figured out how to generate the MOBI format through code only to find that Amazon discontinued it in favor of EPUB instead. Fortunately, generating MOBI is highly similar to generating EPUB (same OPF and NCX files), and with just a few tweaks during a morning, I was able to make the EPUB generation from code work. However, even though Kindle now tells me that it prefers EPUB as the primary format, when I drag an EPUB file onto my Kindle, it doesn’t recognize the EPUB file in my Kindle library; my Kindle Paperwhite device recognizes only MOBI files. So I’m not sure what the point of generating EPUB for Kindle is (unless you’re publishing through Amazon). I believe Amazon just converts EPUB to MOBI on devices.
Also, there are some minor styling discrepancies between MOBI and EPUB that I still need to figure out, such as list spacing. But this is an area I plan to become more expert in. I’m not a huge eReader user myself, though I suspect that paper books are waning in favor of digital formats. I would like to be a more voracious reader. I do like reading on eReaders more than physical books, actually. But many dual-column PDFs don’t work well on eReaders, so many times the content I want to read isn’t available.
I plan to put the course content on Amazon through Kindle Self Publishing at some point, but updating that asset looks to be much more cumbersome than I want. I’m constantly tweaking things on my site. You can probably guess that across 900 pages of technical content, the landscape changes frequently. Just yesterday, I was updating the information about the Xweather API, and I’m also planning to move a couple of articles from the Processes and methodology section into a new section on communication, which will also be a space where I publish more articles related to my presentation on How to increase awareness inside corporate walls. I’d also like to broaden the title from “Documenting APIs” to maybe include the word “developer portals” somehow (like “API documentation and developer portals”). The focus has expanded so much beyond REST APIs that the original title no longer makes sense. But I might just leave it as is.
Another issue to figure out is file size. The MOBI file is 250MB in size, and I need to figure out how to compress that. I already wrote some scripts to identify and remove unused images, but the file size might be a real problem given that Amazon charges more to download files beyond a given size. Dividing up the content might solve this problem, though.
From a monetary perspective, I’ve had good success with the advertisements integrated into course pages. I feel like the ad revenue is much more than a book or online course would make, and I don’t really need the money anyway. I get more value from the comments, shares, and other visibility of the content than I would by gating the content with paywalls. I like the content to be visible in search results as well. So when and if I put the ebooks on Amazon, I’ll make them as free as possible.
If you do browse these PDF and eBook formats, let me know what you think. If you spot some style or formatting errors, or have other tips, I’d be interested to hear them. I’m also curious to know what eReaders you use, especially if not Kindle. I am tracking clicks to the various links, and so far PDF seems to be the most popular, followed by EPUB.
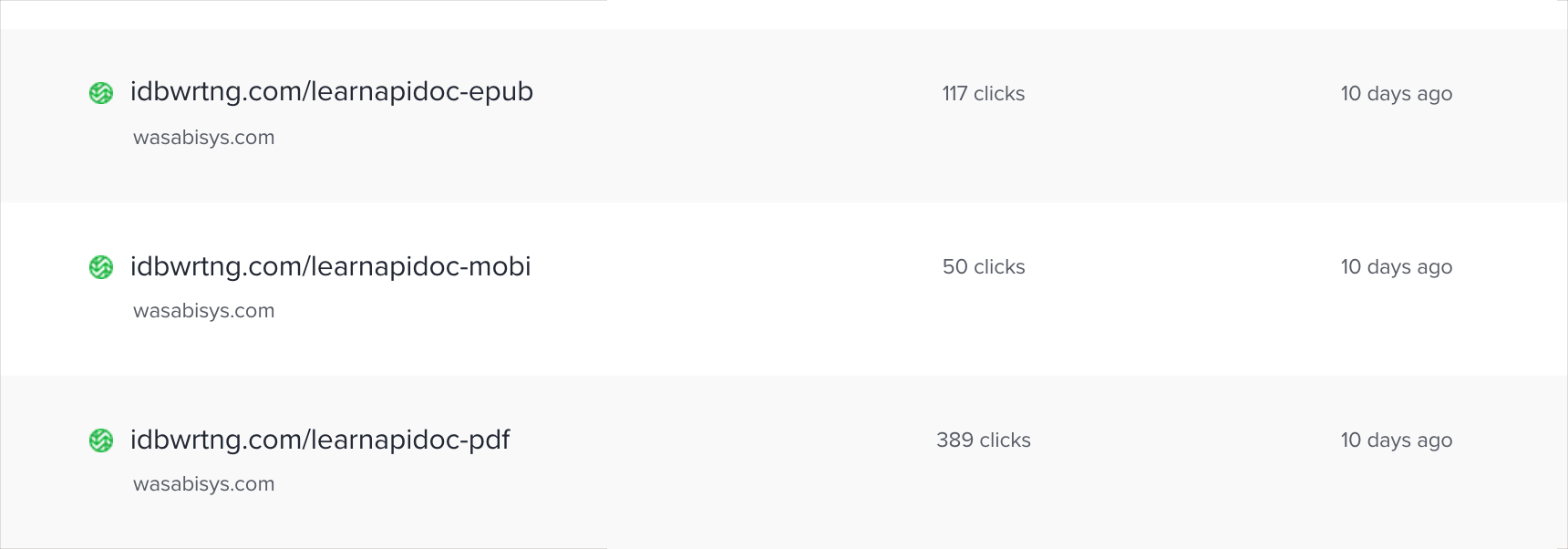
It’s interesting to see PDF win out over other formats, but like I said earlier, PDF viewers allow you to highlight and add notes easily to the content, as well as browse through pages more easily than with an ebook. An ebook might be better suited to other types of non-course content.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.