

Use cases for AI: Synthesize insights from granular data
- Overview
- Using AI in APIs: What works, what doesn't
- Use cases for AI: Develop build and publishing scripts
- Use cases for AI: Understand the meaning of code
- Use cases for AI: Distill needed updates from bug threads
- Use cases for AI: Summarize long content
- Use cases for AI: Synthesize insights from granular data
- Use cases for AI: Seek advice on grammar and style
- Use cases for AI: Arrange content into information type patterns
- Use cases for AI: Compare API responses to identify discrepancies
- Use cases for AI: Draft glossary definitions
Lesson 7 of 11
One of the main ways I use AI is with thematic analysis, which involves identifying, analyzing, and reporting patterns (themes) within qualitative data. After you identify major themes, you can use least-to-most prompting techniques to go into more detail.
I recently used this technique in preparing notes for a book club. It could also could work well for a number of documentation-related scenarios. In this article, I explore using AI for thematic analysis with doc feedback, search analytics, tags and related pages, FAQs, glossary items, bugs, and documentation pages.
Step 1: Thematic analysis
Let me introduce thematic analysis through an example. I run a book club at work focused on auto and transportation topics (since I work with geo-related APIs for maps in cars). I haven’t talked about this book club much on my blog, but it’s something that grew out of my Journey away from smartphones series.
Every month, we read a book and then meet to discuss it. As the book club facilitator, I select the book and prepare notes and discussion for it. Like everyone else, I don’t have a lot of time for this preparation, given that I squeeze it in among work tasks.
The latest book we read was Paved Paradise: How Parking Explains the World, by Henry Grabar. I like to annotate pages as I read because it makes the reading experience more active. I usually finish the book a few days before the book club meeting. In a short amount of time, how do you prepare detailed notes and discussion from a 280 page book covering a variety of topics?
Here’s my process:
- I go back through the book and voice type the key passages and ideas into a Google Doc. (I used to type the notes out; then I discovered voice typing by going to Tools > Voice typing in Google Docs, and it sped things up.) This part is the most tedious because I put stars next to far too many passages when I read. However, collecting this material is key to creating the input source for the AI. I don’t mind if the voice-typed passages have errors because the AI tools are generally great at correctly interpreting the intent and meaning anyway.
- I find about 10 book reviews and copy/paste the review content into the same Google Doc.
-
I ask a high-level question to the AI. I chose Claude.ai because it accepts a large input, and also because the book club doesn’t involve confidential data. (If you haven’t tried Claude, it’s pretty amazing. The large text input allows you to supply more context to the AI, which can prevent the wacky hallucinations and fictitious responses.) Here’s the prompt I used:
The following content contains quotes from Henry Grabar's book, Paved Paradise: How Parking Explains the World. There are also book reviews. From this content, pick out the major themes in the book and the high-level arguments.
Here’s a screenshot:

The result was a list of major themes and high-level arguments in the book. The ability to extract general themes from small pieces of data is a technique used in many domains. For example, when researchers make sense of feedback, they often code the feedback with terms and then quantify the instances of the terms.
The following sections list other use cases for thematic analysis, more applicable to tech comm.
Thematic analysis of desired skills in job ads
I wrote about this technique in Looking at job advertisements to extrapolate the evolution of tech comm. In “The Evolution of Technical Communication: An Analysis of Industry Job Postings” (Nov 2015 Technical Communication Journal), Eva Brumberger and Claire Lauer analyze hundreds of job advertisements, looking for patterns. They want to know what skills employers are seeking for so they can prepare their students to be successful in the job market.
After identifying the skills in the job ads, they quantify the skills to assess trending patterns. From this research, they arrive at a list of desired skills. The most sought-after professional competencies for technical writers/editors include written communication (75%), Editing (51%), Project planning/mgmt (49%), Visual communication (49%), Subject-matter familiarity (45%), Working with SMEs (41%), and Style guides/standards (40%).
Thematic analysis of doc feedback
Affinity diagramming is another common technique used by UX researchers to synthesize user feedback into more actionable groups and themes. An affinity diagramming session starts with writing hundreds of qualitative statements on Post-it notes; then a dozen or so people arrange the Post-it notes into thematic groupings. Finally, someone writes a statement at the top of the Post-it note group that expresses the collection of notes. This technique allows researchers to go from hundreds of points of data (fragmented, ungrouped, and miscellaneous) into actionable insights.
Thematic analysis for search analytics
You could also do thematic analysis for search analytics. Previously, I wrote a post called What’s the point of site search? The problem with site search analytics is that you end up with a lot of little pieces of information that are hard to analyze. Specifically, see the section The actual searches people are making on my blog. It’s hard to extrapolate themes by looking at the individual keywords. If I wanted to analyze the search terms scientifically, I could code each search result with a keyword, then group all searches that have the same keyword, then analyze that grouping to identify common themes, and so on. This task is usually too tedious for any technical writer to undertake.
But if you plug the same long list of keywords into Claude.ai and use a thematic analysis prompt, you can quickly arrive at thematic analysis:
Prompt:
The following is a list of keywords that people search for using my site search. [Paste of search keywords from [The actual searches people are making on my blog](https://idratherbewriting.com/blog/pointless-to-implement-site-search/#actual_searches).] From this list of keywords, synthesize the predominant themes.
Response:
Okay, here is my analysis of the key themes based on the list of keywords you provided:
- Technical writing skills - There are many keywords related to core technical writing skills like "technical writing," "simplifying complexity," "readme," "instructions," "troubleshooting," "getting started," "tutorials," "API documentation," etc. This indicates visitors are interested in developing technical writing abilities.
- Tools and technologies - Terms like "AsciiDoc," "DITA," "Markdown," "Jekyll," "Hugo," "CMS," "static site generators," "git," "GitHub," etc point to an audience looking for information on documentation tools and coding/technology skills.
- Career development - Keywords such as "skills," "interview," "salary," "freelance," "laid off," "starting as technical writer," and "jobs" suggest visitors want to develop their tech comm careers, find work, and interview successfully.
- Writing techniques - Queries like "minimalism," "every page is page one," "simple language," "progressive disclosure," and "context-sensitive help" revolve around writing methods and best practices.
- API documentation - Many keywords focus exclusively on API documentation, like "API documentation," " OpenAPI," "API reference," "endpoint documentation," "Swagger," etc. Developing API skills is a priority.
- DITA and structured authoring - There is heavy emphasis on XML, DITA, content types, specialization, etc, pointing to strong interest in structured authoring.
Any time you have a thousand pieces of information that you need to analyze for patterns, your first-stop shop for analysis (given limited bandwidth and time) could probably be an AI tool.
Thematic analysis for tags and related pages
Another use case could be tagging pages. Most technical writers work in developer portals with hundreds of pages of content. In many cases, it’s a best practice to create a taxonomy describing the content, so that pages with the same taxonomy terms can be surfaced as related pages. As a user, you’re probably accustomed to seeing Related pages or Recommended pages.
To power these related pages, writers would need to index the keywords from each page in their content, and then standardize those index keywords in a structured list of terms (for consistency). From those keywords, a script could surface other pages that have similar tags.
Again, this sort of task is extremely tedious. There’s a reason many of us became technical writers rather than professional indexers. AI tools could speed up this indexing and tagging process considerably.
Thematic analysis for FAQs
Another use case for thematic analysis is with FAQs. Some websites have hundreds of FAQs for their sites. When I worked at Amazon, we had a giant FAQ document that writers kept adding to over the years. Eventually we divided it into smaller FAQs (see Index of FAQs), but even this index page was embarrassing. Generally, it’s better to structure the information from FAQs into the topics where the information belongs, plugging the information into the larger body of information rather than cobbling it together in a random list. (For more on this topic, see The problem with Frequently Asked Questions (FAQs) in documentation.)
Using AI tools, you could group the individual FAQs into themes. With this approach, you might go from 100 randomly ordered FAQs into half a dozen thematic groupings. But then from those thematic groupings, you could use a prompt like this to match the FAQs with their appropriate pages:
The following is a list of FAQs for my site [paste FAQs]. Here also is a site index listing all the web pages of my site [paste index of web pages]. For each FAQ, list the most appropriate web page this information should appear on.
You get the idea here. There are certain scenarios where you have lots of individual pieces of information. From these pieces, you can use AI tools to synthesize larger groupings and themes. This is one area that AI tools might perform much more efficiently than humans.
Thematic groupings of glossary items
Another use case for thematic analysis is with glossary items. With glossaries, you have hundreds of small pieces of information. Usually, the glossary items have a searchable filter at the top, and people come in, look up one term, and then continue on in their information journey.
But what if you want to help users learn a collection of terms for a specific situation? For example, rather than listing hundreds of terms in alphabetical order, you could provide thematic groupings of terms to help people learn specific domains. If you were writing about finance, you might have a “Fixed Income Securities” glossary group that includes bond, yield, maturity rating, credit rating, and coupon rate. You could create another grouping titled “Investment Fund Types” that includes the terms mutual fund, index fund, exchange-traded fund, hedge fund, and money-market fund.
By creating specialized glossaries, you draw attention to related terms and can help people differentiate between the terms.
Thematic analysis of bugs
In looking for scenarios to apply thematic analysis, who can forget bug lists? Suppose you have 150 bugs in your team’s ticket management system (e.g., JIRA). You probably want to group them into different sublists so that you can tackle them more efficiently. You might want to group all the bugs about the “ACME API” in one list, all the bugs about the “Omega API” in another, all the bugs about the “service widget” in another, and so on. Sorting through the bugs is time consuming and tedious.
To leverage AI, you could first use summaries to generate more appropriate titles for each of the bugs. Then you could export the bugs into a long list. Feed that list into an AI to sort them into thematic groupings. Then from those groupings, apply group tags to the bugs.
But don’t stop there. What if you were to analyze the bugs of all the software teams you support? Let’s say you support 5 teams, and each team has their bugs in different components. Export the bugs of a component, then feed them into an AI to group and classify the bugs. Prompt the AI to identify common patterns. Using this technique, you could identify problem areas to focus on. In my experience, many engineering bugs could benefit from some documentation updates (clarifying notes, notes about gotchas and bugs, etc.), but engineering teams don’t often think of the bugs as documentation-related. Reading through random bugs tends to be more tedious than tech writers can stand.
Taking this one step further, suppose you’re an internal documentation team that supports hundreds of engineers. You have limited bandwidth and must identify which projects to support. Where do internal developers feel the most pain? Which projects have the most usage plus the most tickets?
Here again you could leverage AI for the analysis. You likely have a list of the most popular pages (based on your analytics). You also have a long list of keyword queries (from search analytics). Then finally, you have a list of hundreds of bugs. Plug that data into an AI and see if you can use its analytical engines to arrive at the most important projects to work on.
Thematic analysis of documentation pages
Finally, let’s explore one more area where thematic analysis might apply: organizing documentation. In every documentation project, you have a long list of individual topics. As part of the organizing task of documentation, you typically group those topics into different folders. The many folders then form the sidebar groupings in our help systems. For this API course, there are about 15 different folders, each with an average of 10 or more topics.
Figuring out the right way to organize topics is not easy task. If you’ve ever flipped the tables and looked at a help system from the perspective of a user, you know that locating the right topic is anything but intuitive.
As a technical writer, if you want to get your documentation system’s organization right, the best approach is to have a handful of real users do a card sort with your topics. You could print your topics on little pieces of paper and have users arrange them into the groups that make the most sense. (Tools like Treejack offer digital card sorts.) But who has time to actually do this? Most technical writers don’t have users at their disposal, nor the bandwidth for user research.
In this scenario, you could use AI to do two things:
- You could ask an AI to group your topics into the most logical groupings by theme, based on the topic titles. This would at least give you the benefit of another perspective. You could even prime the AI with a specific persona to induce a different perspective (e.g., AI by saying, “You are a new user…”, “You are a business executive rather than a coder….” “You are an advanced developer…”)
- Then you could analyze the AI groupings against your own groupings to identify areas that might be less intuitive. If the AI tool predicts that a topic about “API errors” would more logically appear under “Support” than under “API reference,” a move might be worth considering.
Each of these scenarios involves sorting and grouping lots of little pieces of information. This is a common cognitive task that we perform countless times in our role as technical writers. (Information synthesis is a topic I wrote about in my series on Simplifying Complexity: Principle 3: Ensure information harmony in the larger landscape.) We are frequently taking small pieces of information and fitting them into a larger information landscape. Consider using AI tools to assist with these tasks.
Step 2: Expansion of detail
Now that we covered thematic analysis in a variety of scenarios, let’s explore the logical follow-up to the thematic analysis: detail expansion. Specifically, expanding the detail using a prompting technique known as least-to-most prompts.
In the context of AI prompt engineering strategies, least-to-most prompts involve asking for high-level information/outlines first, followed by subsequent prompts that dive into each point for greater detail.
In Prompt Engineering for Generative AI, James Phoenix and Mike Taylor describe the least to most prompt technique as follows:
The Least To Most prompt technique allows you to sequentially create/extract more knowledge in any topic.
This is often a series of prompt chains, with each prompt input utilizing the generated information from previous prompt outputs.
This technique can also be applied to code generation, as demonstrated in a Flask Hello World app example.
…
First, we start by asking the AI to outline the basic architecture for a simple Flask Hello World application.
…
Next, we request the AI to provide the code snippet for a simple “Hello World” route in Flask. (See “Chapter 2. Standard Practices for Text Generation”)
In other words, you start by asking for high-level information first; then based on the responses, you zoom into the detail for each response.
You already asked for high-level information through the thematic analysis prompts. It’s now time to zoom into the details of those high-level themes or outlines.
Book club
With my book club, after I gathered a list of high-level book themes and arguments, I wanted to provide more detail about each one. So I followed up those thematic analysis prompts with this:
Prompt:
Now I want to zoom in on some of these arguments, starting with this one: "Required parking for housing and other buildings has limited the creation of affordable housing and driven up costs. Parking can add tens of thousands of dollars per unit, pricing out lower income residents." Articulate the logic in as crisp of a way as possible. What is the assertion, what are the supporting reasons, and what's the premise? Any faulty assumptions in the reasoning?
Here’s a screenshot:
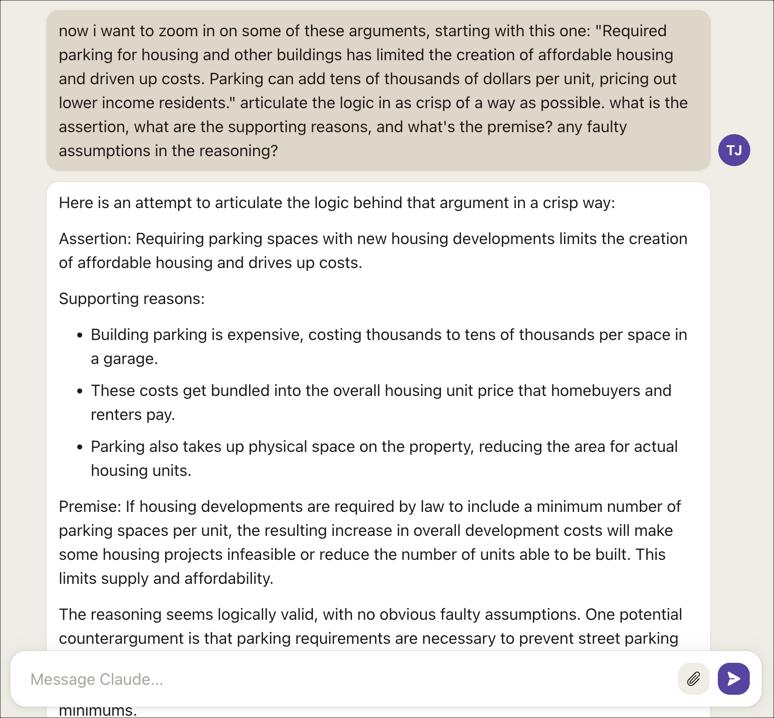
Because I’d read the book, I could easily distinguish whether Claude’s responses were on target. About 80% of the time or more, it was accurate—in part because I’d provided the AI with accurate input sources. My approach in compiling the discussion notes was to clarify and articulate the author’s main arguments, and AI’s responses made this easy.
Could I do this same task myself, without relying on AI? Sure, in the same way I could calculate long-division by hand. It probably would have exercised more critical muscles in my brain to do so, but again, time is the issue.
Overall, this process allowed me to quickly arrive at a good summary of the book’s main arguments. I added some more discussion questions (not using AI) at the end of each section, and I was ready to go. The book club turned out to be one of the best of the year!
Applying least-to-most prompts to thematic groupings
Following up thematic analysis with least-to-most prompts doesn’t always make sense. But for the scenarios I described earlier, here could be some logical next steps to add more detail:
- Feedback. From the general feedback themes, AI can provide more extended summaries of the themes, with some detail. It’s probably not enough to list general categories of feedback; people will want summaries that describe what each category contains.
- Search analytics. Provide descriptions of the analytics trends. It’s not enough to say that there are many keywords searches about “Foo.” You want to follow this up with a summary paragraph that describes the information patterns around Foo keyword searches and why this topic is important to users.
- Tags and related pages. If you have a list of tags for your pages, like I do here, it would be helpful to see descriptions of each tag.
- FAQs. You could use AI to synthesize/integrate the FAQ into the relevant topic. For example, ask the AI where the best place to add a detail about, says, service widget limitations would fit into the topic.
- Glossary items. You could use AI to expand definitions of any poorly defined terms.
- Bugs. You could use AI To describe the general bug trends for each high-level grouping, along with noted patterns for the bugs.
Conclusion
In general, the direction we’ve followed is like this:
- From smaller pieces of information, we synthesized larger themes. In other words, we developed order from chaos.
- After arriving at the larger themes, we zoomed into each theme to provide more detail.
These are flows of information that usually take place unconsciously in our minds as we think through problems. I’ve simply made them explicit here because AI tends to be good at performing these tasks.
Continue to the next topic: Use cases for AI: Seek advice on grammar and style
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.