

What's the point of site search?
- Looking at my own search experience
- Looking at Algolia analytics
- The actual searches people are making on my blog
- Searches with no results
- Conclusion
- Your thoughts and feedback
Looking at my own search experience
I’d like to start by taking a look at the searches I made over the previous day or so. According to Google History, here’s what I searched for:
- Windows chrome
- Windows chrome (Window non-client areas)
- what is a windowed mode windows
- from january 22 to june 10 is how many days
- site:qualtrics.com site intercept
- pet peeve idratherbewriting
- la gear masks
- download photoshop
- nothing added to commit but untracked files present (use “git add” to track)
- git remove files from tracking
- site:idratherbewriting.com facets for tech comm
- 1160 Enterprise Way, Sunnyvale, CA
- what is your review of swiftype
- swiftype
- Cludo
- is algolia worth it?
- how does kendra machine learning work
- delete files from command line
- delete specific files from directory programmatically
- delete list of files from directory programmatically
- regex does not equal
- jekyll don’t publish file if it has frontmatter property
- script to locate all files with certain html property
- jekyll don’t build a file if it has a certain frontmatter property
- how to use a digital multimeter
I won’t bother to explain the reason behind these searches. Each of these searches is peppered with sites I’ve visited. After each search, the visited sites informs me about the terms to search, creating feedback loops that influence the next search query.
Search is critical to how I imagine most of us operate. Maybe your Google history looks different, but mine is filled with dozens of searches a day, especially when I’m stuck with a problem (e.g., git issue) that I can’t figure out.
If search is so central to how we operate, so central to findability, why doesn’t search earn a more prominent place in my daily activities as a professional technical writer?
No doubt it’s because Google takes care of search for me. Because Google is so good, I don’t have to worry about creating my own search for docs.
I recently asked our field engineers how they used search, and most of them also use Google rather than our dev portal site search when looking for content. Even if I implemented an amazing search experience, out of sheer habit people might just continue using Google anyway.
Looking at Algolia analytics
I have Algolia integrated into my blog. Someone from Algolia actually integrated it a couple of years ago as a way to promote Algolia, and they gave me a free starter plan for my content because the number of pages on my blog exceeded the free community plan. Honestly, I don’t look at search analytics that often, though presumably I should be regularly examining the terms people search for to get a better idea of what readers want.
Here’s the search analytics dashboard in Algolia for the past 30 days:
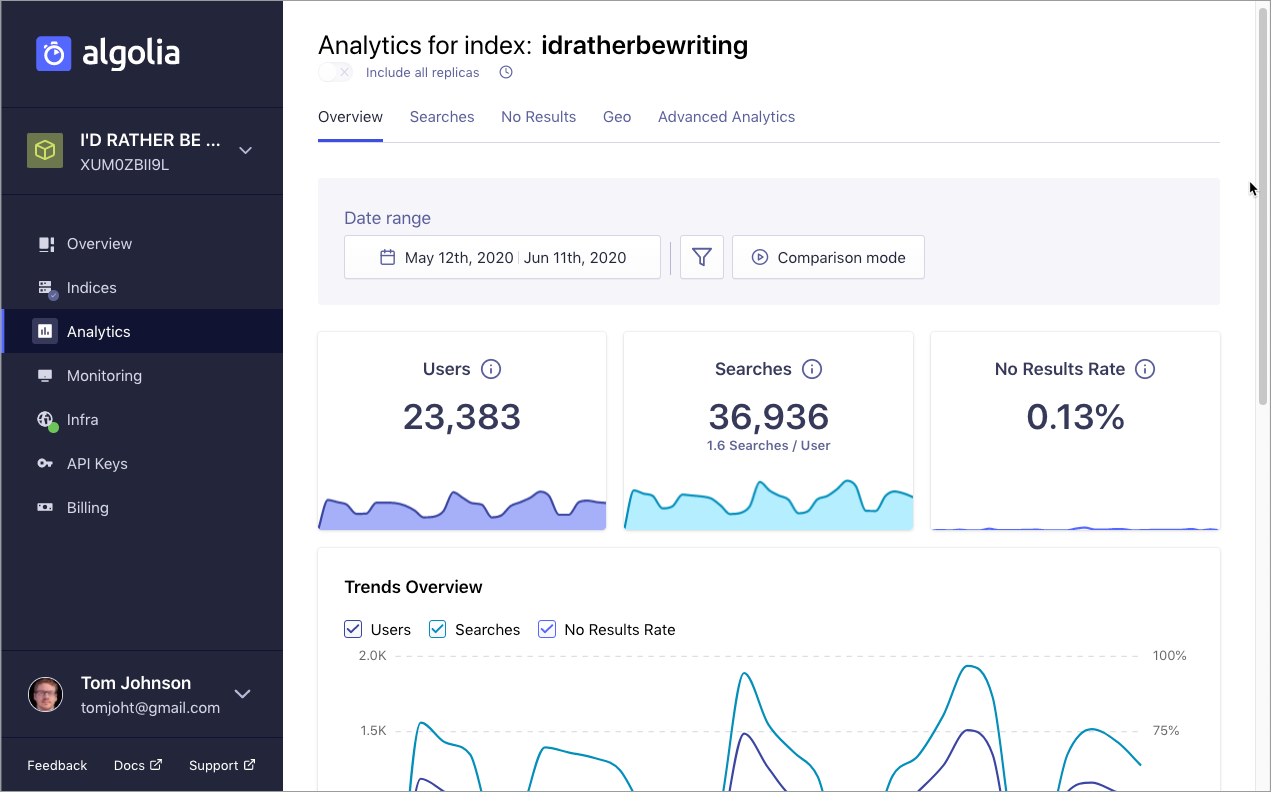
Search analytics retention is only 30 days in my plan (and in the community plan, there’s no retention at all).
Apparently, 23,383 unique users performed a search during the last 30 days. They performed 36,936 searches, or 1.6 searches per user. Holy cow! I didn’t even realize that. Every year when I analyze my analytics, I focus only on Google Analytics and podcast analytics. Have I been missing a huge piece of the puzzle?
Looking more closely at the searches, there seems to be a glitch in the analytics.
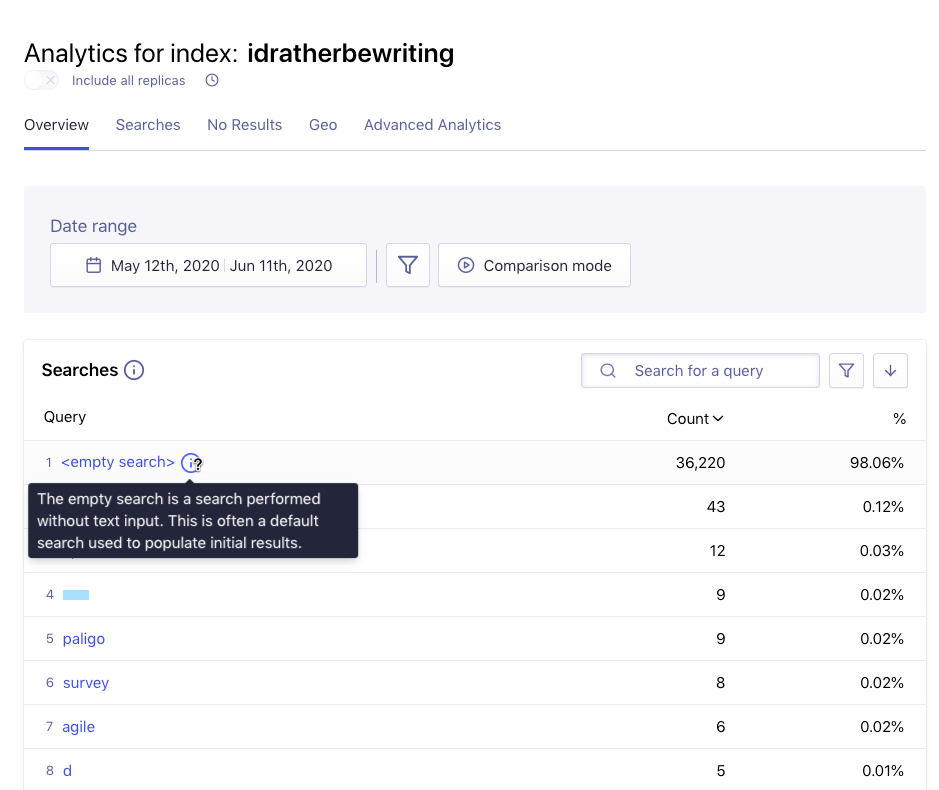
36,220 of the searches are just empty? WTF?
If I look at the actual visitors on my site for the same 30 days by looking at Google Analytics, the count is around 160k page views for 86k users, so the empty search with Algolia can’t be a mere page load but might be users putting their cursor in the search field or something? Here’s my Google Analytics dashboard:
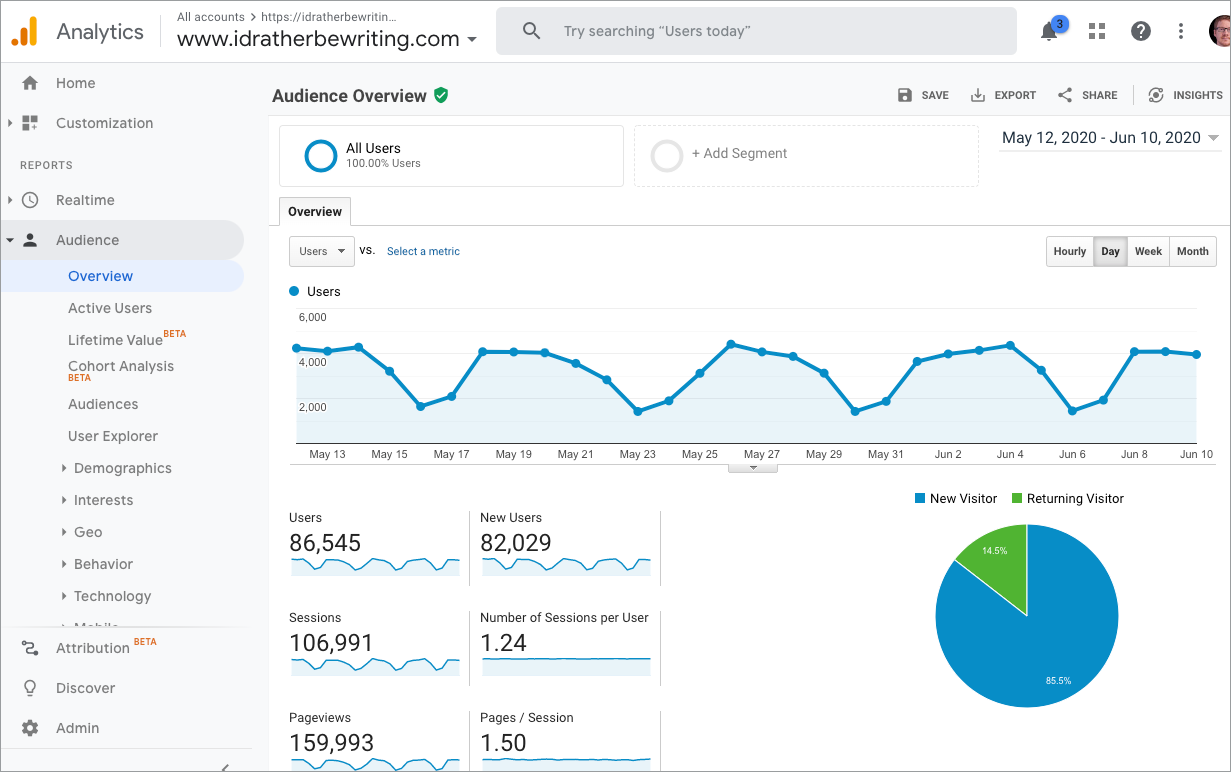
159k page views doesn’t explain the 36k empty searches from Algolia, so I have no idea what’s going on.
The actual searches people are making on my blog
Let’s dive deeper and analyze the actual [non-empty] searches people are making on my blog. Here are the queries:
- api
- paligo
- survey
- agile
- d
- dita
- peter
- w
- markdown
- madcap
- `
- oxygen
- jekyll
- algolia
- analytics
- trends
- swagger
- smes
- developer experience
- resume
- rest api
- postman
- developer portal
-
- /
- +++
- 0
- api
- asciidoc
- beginner
- clickhelp
- cms
- code
- complexity
- content strategy
- dev
- developer
- devops
- docops
- docs-as-code
- e
- fonts
- four childre
- framemaker
- “getting started”
- google analytics
- graphql
- guidelines
- i
- images
- information 4.0
- instructions
- interview
- ixiasoft
- j
- jira
- jjkkk
- job
- minimalism
- oauth
- openweather
- podcast
- portal
- portals
- process
- readme
- readme.io
- release notes
- sales training
- screenshot
- scrum
- sifter
- skills
- style
- t
- technical
- technical writing
- template
- templates
- tools
- ux writing
- wtd
- books
- bre
- breuch
- campbell
- case study templates
- chatbot
- clc
- x
- cloud
- technicial
- tech writing
- code samples
- code smaples
- codin
- colors
- communicator
- companion
- tedopres
- compliance
- conref table
- content creation
- content development
- telecommunication
- content typ
- content warehouse
- context
- context sensitive help
- creative writing
- csh
- customer engagement
- 3rd
- “data dictionary”
- data visuali
- dataviz
- dc webar
- ddd
- derip
- descriptive
- xdocs
- devdoctrends
- develop
- xml to markdown
- developer document
- developer documentation trends
- 2019 stc summit
- 2019
- developer relation
- termly.io
- dev trends
- diagram
- dira
- 2010 16 09
- dita]]]
- dita versus markdonw
- dita versus markdown
- dita video
- dita vs
- diversity
- doc-as-code
- test
- doc plan
- docs
- docs a
- docs-as
- docs as c
- docs as code
- tho
- doc trend
- doc trends
- documentation plan
- documentation portal
- documentation portals
- documentation process
- duin
- ticket board
- easydita
- ebook
- echnical
- ecosystem
- edi
- educational
- endpoint
- end point api reference structure
- end user documentation
- engagement
- epic
- error messages
- every page is page one
- examples
- excel
- f
- faceted sear
- faqs
- fare
- fe
- feedback
- fg
- fla
- flare
- fmla
- tips
- foru
- foundation
- foundational books
- tool
- fpmts
- xx
- freelance
- fs
- fsb
- fshdg
- future tense
- fvg
- fvtfb
- fyam
- g
- ge
- topi
- getting started
- git
- github
- gitlab
- gl
- glossar
- topic-based
- googlr s
- grammar
- grammarlt
- grammarly
- graphics
- topic bbas
- gravel
- gravel sif
- gravel sifter
- guest
- guest
- trend
- gustafson
- header parameter
- headless cms
- herion
- how to write work instructions
- how you write
- http
- https://idratherbewriting.com/
- hugo
- hypeste
- iame
- identities
- illustrator
- troubleshooting
- import wordpress
- in
- informatiion
- troublshooe
- information a
- instructional
- instructional design versus technical communication
- tutorial blog
- integrated
- intere
- ubuntu-16.04.6-desktop-i386
- intro
- issue tracking
- issue trakc
- #NAME?
- iteatio
- iteration
- user
- user-
- java
- javadoc
- javascri
- javascript
- jekyl
- 2010 09 16
- jekyll+
- jellybeans
- jeopardy
- zoomin
- jjkk
- value
- jk
- versio
- job interview
- jonah sch
- json
- json schema
- jupyter
- kanban
- kim sydow campbell
- knowledge base
- kube
- kubernetes
- laid off
- landing page
- language
- leave form
- le plus
- library
- linking
- lisa mel
- lisa meloncon
- lis mel
- logo
- macbook
- 101
- management
- markdo
- 0
- markdown to
- markdown to dita
- markdwn
- markdwon
- mat
- mcmichael
- medical
- melonie mc
- melonie mcmichael
- metrics
- migrating
- visual
- mobile
- modal
- models
- ms word
- n
- nb
- netlify
- new post in simplifying complexity series
- nm
- notebook
- nothing to see here
- o
- <
- online help
- openapi
- walton
- openwest
- oxyen
- ♣♣
- pac
- #NAME?
- pandemic
- para
- paul gus
- perfectit
- personas
- #
- peter
- peter gruenbaum
- pharma
- ph in dita
- ph tag
- plan
- po
- podcass
- washing
- podcasting tool
- washington dc webinar
- web
- portfolio
- posr
- \
- prismic
- privacy policy
- websock
- process documentation
- product analysis for documentation
- programming
- progressive web app
- pwa==
- pythonn
- python projebct
- pythonproject
- python project
- pztho
- qa
- qordoba
- query param
- “questions to ask smes”
- qui
- quick re
- r
- ra
- re
- websocket
- readme.com
- well
- reasons for failure of documentation
- recording of innovation in technical communication keynote at tcworld
- referable content
- reference card
- references
- relationship tables
- releasase
- why simple language isn’t so simple
- renting
- repetitive api
- require login
- resposive
- rest
- *
- ]
- reuse
- rnet
- roles
- ror
- sa
- saa
- saas
- safe
- salart
- salary
- wiki rot
- sample code
- saul carlin
- scedu
- scheduling
- schema.org
- schwartz
- scoping hours
- wine
- screen shots\
- scripting
- scrittura strutturata
- wordpress
- sdk
- search
- search jekyll
- seattle
- secure online help
- select click
- self publishing
- self review
- seth
- shannon
- side navigation
- side nvai
- writing
- simplifying co
- single sourcing
- sitemap
- sjon sh
- skill
- writing readme
- _
- software
- som
- spring boot
- sql
- starting as technical writer
- static site generators
- status codes
- structure
- structured authoring
- zoomin docs
- style
- “style guide”
- style guide
- summary
- survey
- survey data
- survey jonah
- survey jonqh
- survey jonwh
- surveymonk
- synthesis paper
- wtd austra
- table of contents
- tables in dita
- tagging phrases in dita
- taxonomy
- tbl
- tc eserver
- tc.server
- tc server library
- teamworks
- tech
- technica
- wtd may 28
- 90-u
- a
- accessibility
- acrolinx
- 6v b 4m,/\nbvfgevlk7p[poiu
- agu
- 6v b 4m,/_]
- all
- a mini
- analysis questions to ask
- 462
- andrew
- an interface can have static methods.
- annotated
- 40 foundational books for technical writing
- technical
- api challenge
- api docs
- api documen
- api documenta
- api documentat
- api documentation
- api documentation for beginners
- apiiary
- api jeopardy
- api tools
- api versions
- api vizualization
- arduser
- are tech
- article-
- article based
- article based hel
- technical communic
- asciidoctor
- as code
- ator
- aufc
- 9-Aug-18
- aust
- author
- author-it
- avery
- b
- basics of api documentation
- begin
- technical solutions
- beginners
- be repetitive
- berlin
- best practices
- best practices documentation
- blog
- boardk
- book review
Users made 715 searches over the course of a month. What’s bizarre to me is how different the searches look from the searches I make in Google. Most searches are one word searches that hardly seem informative, but I guess users have already narrowed down their search to my site and are adding this as an additional factor. They might want to know, for example, what Tom has written about “berlin.” Searching google for “berlin” wouldn’t make much sense at all, but searching on my site for “berlin” is the equivalent of asking “what has tom said about berlin on his blog.”
Another factor to keep in mind is that my site search is an Algolia Instant Search. As such, results return for each letter you type. Typing “berlin” creates six search operations, one for each keystoke. The analytics only shows the full query, but users might be adjusting their search on the fly based on the responses they’re seeing. Unfortunately, this makes the search analytics less useful.
Overall, these search analytics aren’t that helpful. They don’t really give me any clear direction about anything.
Searches with no results
How about looking at “searches with no results,” which presumably would be a more insightful category in terms of identifying gaps with docs, right? Here’s what people are searching for that isn’t returning results:
- jjkkk
- 462
- 6v b 4m,/_]
- 6v b 4m,/\nbvfgevlk7p[poiu
- 90-u
- an interface can have static methods.
- api jeopardy
- arduser
- clc
- dataviz
- dc webar
- ddd
- devdoctrends
- end point api reference structure
- fg
- fpmts
- fshdg
- fvg
- fvtfb
- gitlab
- jellybeans
- jjkk
- jk
- jonah sch
- jupyter
- kim sydow campbell
- le plus
- lis mel
- nm
- paul gus
- prismic
- pwa==
- pythonproject
- qordoba
- ror
- scrittura strutturata
- survey jonah
- survey jonqh
- survey jonwh
- synthesis paper
- tagging phrases in dita
- tbl
- termly.io
- ubuntu-16.04.6-desktop-i386
- websock
- websocket
- ♣♣
- wtd may 28
I have to wonder if half of these are bots, especially the search for ♣♣. At any rate, the information from search analytics fails to be informative. I can also see the number of searches by location, and there’s an Advanced Analytics option, but it’s a pro feature and requires facet selection in your search.
One trend seems clear: Search analytics are even less helpful than general web analytics. That’s kind of sad, because often when we think of search analytics, we imagine getting hold of detailed information that describes exactly what users are looking for, their terms and phrases, and more. But the reality is not that at all.
With 715 searches conducted over the past 30 days based on 86k users, that means about 0.8% of visitors (on my site) use site search. Granted, people might search documentation more than a blog, but I doubt that percentage climbs up too much.
Conclusion
Overall, is site search a waste of time? If you could capture meaningful search analytics from use of site search, it might be helpful. But if the search analytics are meaningless, and less than 1% of users actually use it, while everyone else uses Google, then why waste time and energy trying to configure site search on docs? Wouldn’t we be better of spending our time and energy focusing on how searches for terms in our docs surface in Google, and optimizing our content for Google rather than a search no one will use?
Unfortunately, due to privacy issues (as well as the competitive use of the information), Google doesn’t show what searches led to your site. Instead, you would need to resort to search engine optimization analysis tools that show the popularity of keywords and phrases and how your site ranks for them, and then draw conclusions about site performance that way.
Overall, site search doesn’t seem to get us any closer to these larger questions: What’s bringing users to the site? What are they looking for? Are they finding it? These questions remain unanswered. Perhaps it’s better to implement live chat features or other interactive widgets on the site to capture more real-time questions from users.
Your thoughts and feedback
If you’d like to share your experience with site search, please take this short survey. This also lets me know whether the ideas in my post have general agreement among readers or are off base. You can review the ongoing results here.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.