

DITA: Folder hierarchy, conref, mapref, and more
This is my second entry in my DITA journey series. Here, in no particular order, I cover a miscellany of DITA challenges – content re-use, maprefs, folder structures, ditamaps, topicsets, and authoring-publishing workflows.
Content re-use
DITA allows you to re-use content in several different ways. The most obvious way is that you can use the same topic in different maps through the topicref element. This allows the whole topic to be re-used. But if you have smaller re-use needs (more like “snippets” rather than topics), you usually use the conref tag.
Here's how you apply the conref tag. Tag the source you want to re-use with an ID attribute. For example, you might tag a note as follows:
<note type="warning" id="tightening_warning">Do not overtighten the bolts with a loose-fitting wrench. Doing so may strip the bolts, making them impossible to remove.</note>You may have a lot of little content snippets like this, as well as reference tables or other re-usable information that you want to reference. I put these into a compilation topic (ditabase) because the ditabase file type, while discouraged as a topic container for regular content, accepts any topic type (task, concept, reference, and more in any combination and number). I'll call this ditabase topic snippets.dita. The topic's ID is #notes123.
In my bicycle maintenance guide, I may want to re-use this warning in lots of different places – essentially whenever the user is tightening a critical bolt.
To insert this snippet of text into another topic, I use the conref tag as an attribute on a similar tag, like this:
<note conref="snippets.dita#notes123/tightening_warning></note>If your snippets.dita file is in another folder, you'll need to supply the correct path before the file.
Note that the conref attribute must be added to an element of the same type. If your source file were p id="tightening_warning", you couldn't add this conref attribute to note id="tightening_warning".
Also, when you're processing your ditamap, be sure to include the ditabase file that your topic references. You include an attribute called processing-role="resource-only" to include the topic resource in the map but not show the topic in the output itself. Your ditamap will look something like this:
<map>
<title>Bicycle Maintenance Guide</title>
<topicref href="assembling_the_bicycle"/>
<topicref href="snippets.dita" processing-role="resource-only"/>
</map>Mapref
In creating ditamaps, when you refer to ditamap files instead of dita topic files, you can use mapref. You could also use topicref with the attribute format="ditamap", but if you forget that attribute, your output won't work. So you'll be less prone to error by using mapref for ditamaps and topicref for topics. Maprefs were introduced in 1.2.
Note: Speaking of 1.2, a lot of DITA techniques and information on the web and in books address DITA before 1.2 was released. This is particularly true of keyrefs. Try to keep this in mind while reading DITA content via web searches. DITA 1.2 was released in December 2010.
Folder structure and ../ path in ditamaps
Figuring out how to organize the DITA files has been a challenge for me. By default, in a ditamap, the ../ format, which takes the relative URL up a folder level (instead of drilling down a level) isn't supported by the Open Toolkit (OT). This means your ditamaps need to be in the root level so that all files they reference are either at the same level or in a subfolder.
OxygenXML has a workaround for the ../ limitation. You open the Transform dialog, edit your output, and change the fix.external.refs.com.oxygenxml parameter from false to true. DITA 1.3 will apparently fix the limitation when released as well. I decided to apply Oxygen's fix so that I could use ../.
Knowing that DITA's source files would probably result in a lot of little files (which I assemble together through maps), here's how I decided to organize my content.
root
root ditamap (includes maprefs to each sub-ditamap)
- folder
- ditamap_1
- topic_a
- topic_b
- topic_c
- folder
- ditamap_2
- topic_d
- topic_e
- topic_f
- folder
- ditamap_3
- topic_g
- topic_h
- topic_i
- folder
- snippets
- keyrefsThe paths in DITA matter, so you can't just start moving files around without breaking references in ditamaps. Of course some DITA setups are database rather than file-driven, so this point doesn't apply to those DITA workflows. Additionally, a DITA CMS can probably update all references to a topic you move. But I'm working with DITA in its most basic form: as a system of files.
Why did I choose to organize the files and folders this way? I think managing all content in one large map is too onerous – hence the submaps. The snippets and keyrefs are common files, so they are referenced by all ditamaps.
Additionally, if each folder's content is surfaced through a ditamap, I can simply work with content at the folder level, referencing maps instead of individual topics (unless I need more granular detail).
topicset (container topics)
When you assemble the topics in ditamaps, sometimes you may want to group several topics together to form one coherent unit. The word “topic” in DITA doesn't distinguish between container topics and building-block topics. However, there is an element called a topicset. The topicset can contain several topics and also take an ID, which lets you re-use the topic as one topicset.
The topicset is an important element because, as I mentioned in a previous post, my biggest fear with DITA is information fragmentation. Here's an example of how the topicset might be used to combine several subtasks into one topic:
<topicset id="replacing_broken_spokes" navtitle="Replacing broken spokes" href="about_broken_spokes" chunk="to-content">
<topic href="remove_broken_spokes" toc="no"/>
<topic href="remove_the_cassette" toc="no" />
<topic href="replace_the_spoke_nipple" toc="no" />
<topic href="reattach_the_cassette" toc="no" />
</topicset>Each of these topics are sections or subtasks for the general task of replacing broken spokes. Most of the topics here are numbered steps. However, the task element permits only one step list per topic, so I couldn't put all of this information into one topic without creating in a really long list of steps. I break them out into separate task elements and combine them through a topicset.
Organizing the content this way also frees me up for greater re-use opportunities, should I need them.
Notice that the topicset includes an attribute called chunk="to-content". This attribute will merge all the separate topics into one topic file. You could also keep them as separate files grouped in a content folder in the TOC navigation, but again, I think that practice will likely result in information fragmentation, where the coherence of information is shattered into lots of separate pieces, none of which fulfill the user's goal.
Notice also that the toc="no" attribute is specified for each element in the topicset. Without this attribute, the subtasks would appear in the table of contents and simply jump to the place on the page (rather than opening up new pages).
Also, the topicset element has an href as well. This topic is an overview to all the subtasks. I wanted it nested under the topicset title rather than under its own subtitle.
One problem with this kind of organization is that, while this topic renders as one unit, Oxygen's webhelp search surfaces each unit separately. I'll have to figure out how to suppress each unit from showing up in search.
Authoring-publishing workflows
Another question I've had is how to best author DITA when I'm still developing the content itself. Should I continue authoring in Google Docs and then format it all into DITA once the content is finalized, or should I structure the content in DITA from the start, even if it keeps changing while reviewers pick through it?
I decided that it's easier to structure the content in DITA from the start. Otherwise it's too tedious to run everything through a publishing process afterwards. The more the syntax looks second nature to me, the better.
To avoid focusing too much on the tags while authoring content, Oxygen allows you to make the tags semitransparent. This is a nice view that helps draw attention to the text. (I only wish the section titles were more bold.)
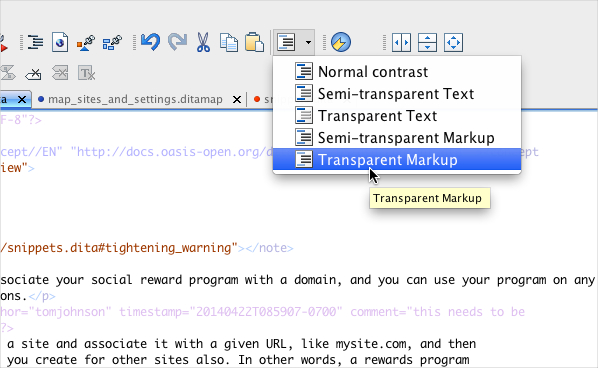
To submit the draft to engineers for review, I output the HTML and paste it into Google Docs. Engineers make comments, and I make the changes in the source DITA files and mark the comments as resolved. When I'm done making all the changes, I output a new version of the file and replace the entire Google doc. The comment history is still retained, though you can't restore the comment.
Where you want to preserve comments in the content, you have to insert the comments using DITA tags. You can do this a couple of different ways. You could switch to the Author view and look for the comment button ![]() . Place your cursor where you want to insert the comment, and click the comment button. Oxygen will insert code that looks something like the following:
. Place your cursor where you want to insert the comment, and click the comment button. Oxygen will insert code that looks something like the following:
<!--?oxy_comment_start author="tomjohnson" timestamp="20140422T085907-0700" comment="Sample comment: This section needs to be verified by engineers."?-->For<!--?oxy_comment_end?-->You could also use the draft-comment tag to accomplish the same thing.
<draft-comment author="Tom" time="4/22/2014">Sample comment: This section needs to be verified by engineers.</draft-comment>By default, comments won't show in the output. To get the comments to show in the output, edit the transformation scenario and set the args.draft parameter to yes.
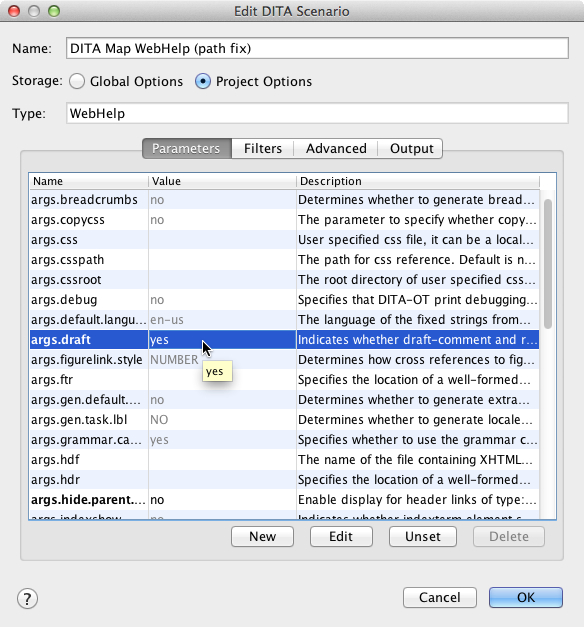
From my brief experimentation, only draft-comments appear in the output when setting this parameter to yes. The comment format inserted through Oxygen's code (when clicking the Comment button in the Author mode) doesn't appear.
Of course engineers will probably prefer to always use Google's commenting capability, so I'm not sure whether switching between the two is a good idea. I'll have to see what works.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.