

Dynamic content filtering with OxygenXML's webhelp output
One of the little tricks I’ve implemented with OxygenXML is dynamic content filtering. Our product supports four different programming languages – Java, PHP, C++, and .NET. Rather than producing 4 separate outputs, I produce just one output and provide a content selector option in the header.
Here’s a topic in my DITA QRG that contains a link to a demo of the content filter.
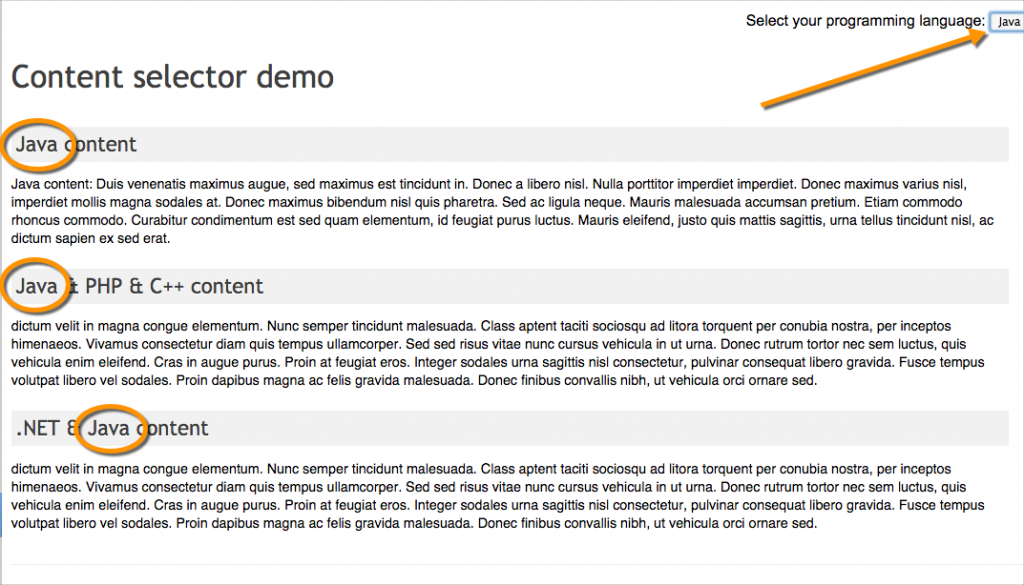
When you select an option in the upper-right corner, the content dynamically changes on the page to show only that option.
This is a bit of a magic trick, and when you see behind the curtain, it’s much less impressive. Basically I have different styles associated with different content. When you select a menu option, it triggers a jQuery style switcher plugin to add a class to the body tag. Then based on my styles for that body class, content is either hidden or shown.
As an added bonus, any items in the table of contents that have the same class will also be either hidden or shown. (Given that OxygenXML’s webhelp is a frames-based output, including the TOC is harder than it seems.)
I described the method for implementing my dynamic content filtering here: Create a content selector. To see a demo of the content selector, see Content Selector Demo.
Limitations
There are a few limitations with the method I’ve used here. The hidden content will still appear in search results, because the search doesn’t care which elements certain styles are using. Also, if you’re using the mini-TOC method any hidden h2 sections will get rendered into the mini-TOC.
Also, I couldn’t figure out how to get the menu selector to appear only for specific pages. It only appears globally. One problem is that the selector code resides in a header file, with code that is only valid in the XHTML header file format, not in regular DITA topics. (I tried inserting the content post-build through jQuery’s append method, but for whatever reason, it didn’t work.)
Other ways to go about dynamic filtering
There are probably better ways to go about dynamic content filtering. With a database model for help, the option a user selects could determine how content is queried in real-time from a database. In that model, content wouldn’t just be hidden – it would not be in the source code at all. (But if you go that route, you have a database to deal with.)
You could also use jQuery tabs to provide a similar experience as dynamic content filtering. Check out this Github pages tutorial. Select an option under “What git client are you using?” You’ll see the subsequent steps change.
From what I can see in the source code, the author is simply using jQuery tabs. Choosing a tab determines what is shown below. It’s probably a more standard way to approach this problem, and I’ll try to go this way in the future.
Advantages of dynamic content filtering
What’s the advantage of having one output instead of four? First, you have a lot fewer outputs to worry about. Instead of pushing to 4 outputs, I push to 1. And actually, I have two product variants (each with 4 programming languages), so if you’re using separate outputs, 2 x 4 = 8. I deliver to both internal and external locations, so with separate outputs, 8 x 2 = 16.
I might also have two different version releases, so with separate outputs 16 x 2 = 32. See how that number begins to grow and spiral out of control? If you make one little update, you have to push 32 outputs out to different directories. It’s much easier to keep the number of outputs to a minimum through dynamic content filtering.
Also, it’s a lot easier to review the content with fewer outputs. And for users who may be curious to see how the same technique is implemented across different languages, it allows them to quickly compare the content for other programming languages.
I’m curious to know if you’re implementing dynamic content filtering for your content. Are you producing many different outputs for different audiences, or one output that users can customize on the fly based on what they want to see?
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.