

Implementing ScrollSpy with Jekyll to auto-build a table of contents
I mentioned in a post last week that I'm experimenting with a Jekyll prototype for technical documentation.
I stumbled upon one of the coolest and most interesting topics a few days ago while integrating "ScrollSpy" on Jekyll. ScrollSpy is a dynamic feature that "spys" on the headings as you scroll past them and dynamically highlights the active heading in your mini-table of contents.
What is ScrollSpy
To better understand ScrollSpy, go to one of the content pages on the Get Bootstrap site and just start scrolling down -- you'll see the navigation on the right dynamically highlight the TOC heading you're viewing.
Here's a short video showing ScrollSpy (expand the video to full-size for better readability):
Bootstrap and Jekyll
Bootstrap, probably the most popular framework for web designers, uses Jekyll to build their documentation. See the note on their readme.md in Github:
Bootstrap's documentation, included in this repo in the root directory, is built with Jekyll and publicly hosted on GitHub Pages at [http://getbootstrap.com](http://getbootstrap.com). The docs may also be run locally.
Bootstrap is particularly interesting and relevant because they provide ready-made components to build your own sites. For example, do you need an label? Copy and paste a little snippet of code and you have it.
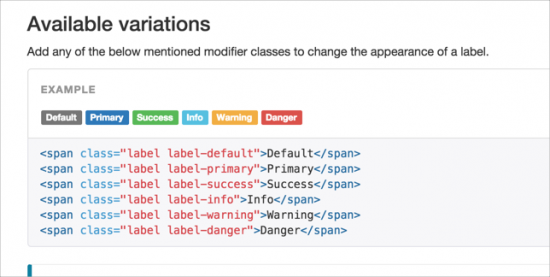
Do you need a dropdown menu, a font icon, an alert message, or even a "jumbotron"? No problem, just copy and paste little snippets of code from Bootstrap's site -- browse the components here and the /css. As long as you have the Bootstrap library and JavaScript file referenced in your HTML, the Bootstrap code works. (And it's kind of like magic, I have to say.)
Bootstrap is also interesting because their site is built on Jekyll, and you can actually download and install the whole Bootstrap site on your local machine and freely fork it. Here's how to install Bootstrap locally. Or see my abbreviated instructions below.
Installing Bootstrap's site locally
Assuming you're on a Mac and have Ruby and Node package manager (npm) installed, do the following to run getbootstrap.com locally:
- Open Terminal and make a directory called bootstrap:
mkdir bootstrap - Go to http://getbootstrap.com/.
- Choose Download source.
- Extract the zip into the bootstrap directory you created in step 1 so that the contents of the downloaded folder are directly inside of your new bootstrap directory.
- Change into the bootstrap directory:
cd bootstrap - Change to admin privileges (if necessary):
sudo su - - Install bower:
npm install -g bower - Use bower to install bootstrap:
bower install bootstrap - Install rouge syntax highlighter:
gem install rouge - Install Jekyll:
gem install jekyll - Build Jekyll:
jekyll build - Initiate the Jekyll server:
jekyll serve - Browse to the local server address shown, such as
http://0.0.0.0:9001/.
(If Chrome pushes this address to a search, replace 0.0.0 with localhost.)
You should then see something like this:

How Bootstrap implements Scrollspy on their site<
I was particularly interested in how Bootstrap implemented their ScrollSpy feature, because unfortunately the full functionality doesn't seem out of the box with the ScrollSpy template provided on Bootply, which is a site that provides ready-made templates for building websites using the Bootstrap framework.
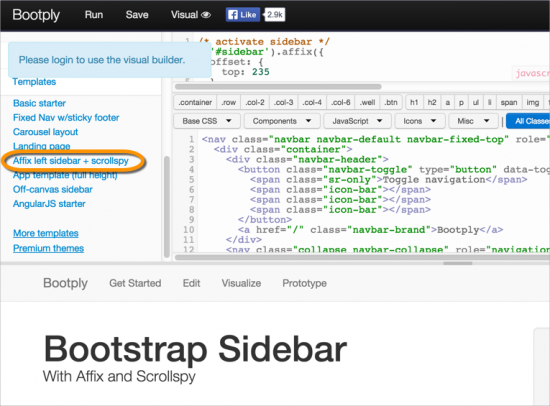
I downloaded and built the Bootstrap site locally because I wanted to see how it was put together, particularly the ScrollSpy sidebar. First, they use both grunt and bower to automate some of their building. Honestly, I'm still a bit new to those technologies, so I'm not entirely familiar with them. But the Jekyll site I am more familiar with.
Let's look specifically at the CSS page here, which is inside docs/css.html in the download. In the code, this isn't one long page. Each of these sections is a separate file. They are pulled together through includes:
{% include css/overview.html %}
{% include css/grid.html %}
{% include css/type.html %}
{% include css/code.html %}
{% include css/tables.html %}
{% include css/forms.html %}
{% include css/buttons.html %}
{% include css/images.html %}
{% include css/helpers.html %}
{% include css/responsive-utilities.html %}
{% include css/less.html %}
{% include css/sass.html %}So the CSS page on getbootstrap is really about a dozen pages all stored in the _includes/css directory.
In Jekyll, layouts are determined by the default.html file in the _layout directory (unless another layout is specified by the page). In default.html, the bootstrap sidebar section contains some if-else logic:
<ul class="nav bs-docs-sidenav">
{% if page.slug == "getting-started" %}
{% include nav/getting-started.html %}
{% elsif page.slug == "css" %}
{% include nav/css.html %}
{% elsif page.slug == "components" %}
{% include nav/components.html %}
{% elsif page.slug == "js" %}
{% include nav/javascript.html %}
{% elsif page.slug == "customize" %}
{% include nav/customize.html %}
{% elsif page.slug == "about" %}
{% include nav/about.html %}
{% elsif page.slug == "migration" %}
{% include nav/migration.html %}
{% endif %}
</ul>These if-elsif statements basically say, for example, if the slug for this page is equal to css, then include the nav/css.html file here.
In the nav/css.html file, the sidebar nav looks like this:
<li>
<a href="#overview">Overview</a>
<ul class="nav">
<li><a href="#overview-doctype">HTML5 doctype</a></li>
<li><a href="#overview-mobile">Mobile first</a></li>
<li><a href="#overview-type-links">Typography and links</a></li>
<li><a href="#overview-normalize">Normalize.css</a></li>
<li><a href="#overview-container">Containers</a></li>
</ul>
... [and so on...]It continues for quite a while, because there are a lot of sections on that page.
Basically, each of the links in these sidebar sections corresponds with the heading ID tags in the regular page (css/overview.html, and so on).
If you look at css/overview.html, you can see the ID on each heading. For example:
<h3 id="overview-doctype">HTML5 doctype</h3>See how the ID on the heading corresponds with the link in the sidebar? That correspondence is what allows ScrollSpy to work.
(BTW, I realize that my description is probably a bit cryptic, especially if you're new to Jekyll. But if you do download Bootstrap's site and start poking around with how it's put together, it will become more clear.)
Hard-coding Header IDs versus automating the IDs
It kind of surprised me that the IDs and sidebar links are hard-coded in the Bootstrap site. I'm assuming they're hard-coded because the IDs for each heading aren't a one-to-one mapping with the heading text, which is how auto-toc generators usually do it. Instead of rendering the ID for the heading "HTML% doctype," it's coded as "overview-doctype" (which may have been the original heading title). That's a lot of work just to get ScrollSpy working.
With a bit of fiddling (okay, with a day of mesmerizing trial and error), and reading this insanely helpful blog post -- Bootstrap Docs Sidebar Explained -- and copying and pasting some code from this awesome bootply template here, I managed to get ScrollSpy working on my Jekyll prototype!
But here it gets better. I found an auto-toc generator built specifically for Jekyll. I integrated it and voila, it freaking worked!!! I no longer had to manually code the links in the sidebar, because the auto-generator created them based on the heading IDs that were auto-rendered by the Red Carpet Markdown extension processor. I was floored.
Here's a demo of scrollspy in my prototype.
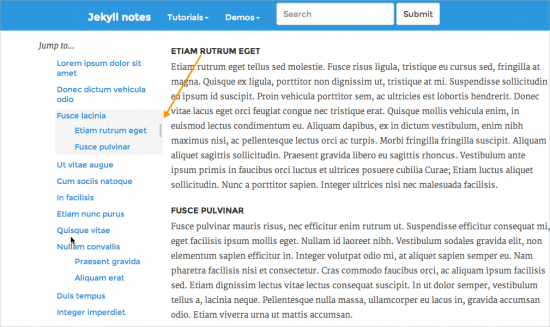
BTW, this Jekyll site is a work in progress, and I'm far from finished. (Once I get it finished, I'll push it out to github for anyone to fork.) Also, don't pay attention to the other content for now -- the text is just my notes on various Jekyll things (but I'll be adding to it).
BTW, to implement ScrollSpy on your own theme, make sure you use Markdown for your heading syntax.
## sampleI'm using the Red Carpet markdown extension (which I think comes bundled with Jekyll) configured as such in config.yml:
markdown: redcarpet</p>
<p>redcarpet:
extensions: ["no_intra_emphasis", "fenced_code_blocks", "autolink", "tables", "with_toc_data"]
highlighter: pygmentsWhen the page renders to HTML, IDs get auto-generated for each heading. That's what the with_toc_data option does.
Fortunately, the Markdown conversion to HTML happens before the auto-generated TOC, so it all works out in the end.
Without this auto-generation of heading IDs, I'd have to hard-code everything like the Bootstrap site does. Bootstrap probably doesn't use this auto-generated TOC method because their docs are coded entirely in HTML, not Markdown. This is probably because they're dealing a lot with HTML (okay, almost exclusively), so it would confuse people to see a mix of Markdown and HTML in the source, especially since people are pasting code snippets from Bootstrap and may or may not be using Markdown.
A small critique of ScrollSpy on Bootstrap's site
Although I really like Bootstrap's implementation of ScrollSpy, I'm not so sure I entirely agree with everything. Their pages are perhaps too long, and that's why they collapse the subheadings until you land on their parents.
But if you can't see the subheadings at a glance, what's the point of a jump TOC? The whole point of a TOC is to let readers know what's on the page at a glance. If you can't see certain sections until you get to their parent sections, then the jump TOC is not that helpful.
However, expanding all the child subheadings would elongate the TOC too much, extending it below the fold (and thus making the floating fixed scroll impossible), so I agree with their design given the length of the pages. (I still think they could benefit by breaking up their content a bit.)
Screen real estate challenges with ScrollSpy
There's another challenge in implementing the ScrollSpy feature. If you integrate this mini-TOC, you basically give up your sidebar real estate. Where do you put your normal TOC? If you add two TOCs, then you end up with a funny design, or you end up cramping the content in the middle. You can see how cramped the space is in my blog now with the three columns. If you want to add cool graphics, screenshots, code samples, etc., the small content width is going to make that all problematic. You'll end up shrinking your font size to make it fit, and that detracts from readability. Your sidebars will also be narrower, making them less readable. (Here's a bootply template with 3 columns -- kind of looks cramped to me.)
But here's the thing about the regular, comprehensive TOC sidebar. Comprehensive TOC sidebars only work for a specific scope. If you put all your content into that sidebar (e.g., 75+ pages), it becomes meaningless to the user. The trick is to narrow the scope to show enough relevance for the content the user is looking at, but not too much that the user drowns in endlessly expanding hierarchies of folders.
So where do you put your other navigation? You can it in your header, which also floats down and sticks as the user scrolls. You can implement some drop-downs here, but ultimately you need a kind of landing page for all your help items, one that the reader can easily jump back to. The homepage works well for that. This is the design pattern for any massively sized help system anyway. (As an example, see the WordPress Codex's navigation homepage.)
Jan 26 update: See my more recent post, Reinventing the table of contents for my latest approach on the TOC.
ScrollSpy jump locations wrong due to floating header
One annoying problem with ScrollSpy is that the floating top toolbar screws up the anchors. When you click the sidebar links, your pages jump to the top and get overlaid by a floating toolbar. There are some hacks in the CSS I implemented to get around this -- see this post from StackOverflow.
Usability of ScrollSpy
One final question: Does ScrollSpy add significantly to the user experience? Greg Koberger from ReadMe.com said that this dynamic TOC highlighting while users scroll (ScrollSpy) is a highly requested feature he's heard from many devs. You will see this feature in many API doc sites.
For tech writers who chunk up their content into little pages, the ScrollSpy feature probably won't add much. But this feature will allow you to create longer pages without sacrificing readability. It will also help avoid information fragmentation and encourage more of an every-page-is-page-one experience.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.