

Why long-running tasks autonomously carried out by agentic AI aren't the future of doc work, and might just be an illusion
- Examples of long-running tasks
- Results of trying these long-running prompts
- Tasks that involve iterative decision-making based on feedback loops
- Example of iterative feedback loops
- Additional challenges for long-running agents
- Conclusion
For a short video (7 min.) of this post, see this NotebookLM video. The images in this post are from the NotebookLM slides.
As agentic assistants get more capable, I’m seeing more emphasis on long-running tasks. These are tasks that require less human intervention and give more autonomy to the agents to make decisions along the way to achieve the task’s goal. In some ways, it seems like a primary activity for future tech comm work might involve carefully crafting long-running prompts that allow a technical writer to fully automate a task. The tech writer’s role then becomes focusing on designing prompts, instructions, and skills that highly capable autonomous agents can follow to complete the doc-related tasks. The more complex the task, the more complex the prompt.
However, I think this idea seems appealing in theory only. In reality, long-running tasks have limited application and aren’t representative of 90% of the documentation tasks I do. Most documentation tasks involve iterative decision-making along the way based on feedback loops. Although many people would like tech writers to automate their tasks, the reality is that most doc scenarios are one-offs and not repeatable in a prompt that would apply to future doc tasks.
Based on the need for the human-in-the-loop to steer, provide feedback, course correct, and apply judgment all along the way of a process—in constant conversation with an AI agent acting as a thought partner rather than a wholly autonomous agent—I don’t foresee long-running tasks being all that important for tech comm work.
For example, how many people have large prompt libraries full of ready-to-go prompts for all the incoming doc tasks they have to perform? I see prompt libraries surface regularly as popular features to add to sites providing AI guidance, yet I myself don’t have a personal prompt library.
On a larger note, because of the need for this iterative thought-partnership in the content development process, I don’t see how AI can replace a human worker. It’s much more likely that AI augments our processes rather than fully replacing the human-in-the-loop model.
Examples of long-running tasks
Before I dismiss long-running tasks, though, I’ll give some space to them here. Long-running tasks are tasks you might give to your AI agent and then come back in an hour (or maybe 5 minutes, realistically speaking) or so to see the result. I frequently hear about agents running all night or something, which baffles me because most AI agents I use finish in under 10 minutes, or they terminate early due to errors or other permission-granting needs.
Tasks with predefined prompts most likely need to be general quality control tasks. Here are 10 examples you might run:
- Grammar. Identify and fix all obvious grammar and spelling errors in each of the following directories in the documentation.
- Links. Examine the links on each page in the documentation and make sure they are still valid. Identify and fix any links that are wrong.
- Style. Audit all documentation pages for compliance with our company’s internal style guide and terminology list, which you can find here: [provide location]. Flag or correct instances of outdated, non-standard, or inconsistent terms across the docs.
- Accuracy. Check each API conceptual page for accuracy by comparing the assertions made in the conceptual pages against the functionality of the API reference. For topics in the X directory, compare them against the X API reference. For topics in the Y directory…
- Deprecations. Look through the release notes and identify all the elements that have been deprecated in the past year. Then look through the documentation pages and see if those deprecated elements are still used.
- Bugs. Look through each bug in the documentation component and group them based on three categories: ease of fixing, API, and requester. Briefly describe each bug in 1-2 sentences. Look at the provided material in each bug and determine whether the requester has provided sufficient info for it to be actionable. Then arrange the bugs in a list of easiest to most difficult to fix.
- Metrics. Analyze the metrics for the past year to determine three categories: (1) the most popular pages, (2) the pages that users spend the most time on, and (3) the pages that users spend the least time on. Analyze the page content and determine potential reasons for why these pages ended up in these categories. Then analyze the page content and recommend fixes as needed.
- Images. Review all images and screenshots in the documentation. Check for consistency in image styling (e.g., callouts, borders) and verify that the UI elements depicted in the images match the current version of the product interface. Flag or update inconsistent or outdated visuals. Make sure each image has an alt tag and title tag with appropriate content that reflects the image.
- Readability. Run a readability analysis (e.g., Flesch-Kincaid) on all documentation pages and flag sections that exceed 12th-grade readability. For flagged sections, rewrite them to improve clarity and simplicity, maintaining the original technical accuracy.
- Summaries for content optimization. Go through each page and add a summary in the frontmatter. Use these summaries to construct an llms.txt file. The summaries should help AI understand what each page is about, helping these tools locate the right files.
These tasks are probably ones that few human tech writers could do without becoming bored or tapping out after a few hours (especially when applied to a doc site with 100+ pages or more). Also, it’s worth noting: almost none of these issues end up as doc requests that people file for me. Yes, I get the occasional bug about a misspelled word or broken link, but they’re not the bulk of the requests. In my world, almost all doc issues are content-specific requests that would be hard to convert into a long-running prompt.
Results of trying these long-running prompts
I’ve only actually tried a couple of these prompts: the grammar/style fix and the link fix. In both cases, the agents caught and fixed an impressive number of errors. Looking at all the fixes, I thought, geez, I’m really more of a sloppy writer than I realized. Glad no one seemed to notice a lot of these issues. In about an hour or two, I’d fixed 70+ minor cosmetic issues in my docs.
It’s safe to assume that most tech writers feel embarrassed about grammar errors and broken links in docs, and any process that can easily fix them is welcomed with open arms. It could be worthwhile to run most of the above prompts on a regular basis to catch quality issues.
But like I said, this isn’t what most documentation work involves. Most doc requests require a lot more complex decision-making along the way. Instead of allowing the agent to work autonomously, the documentation projects require a thought-partner relationship with the AI, where you have conversations that lead to mutual decision-making.
Tasks that involve iterative decision-making based on feedback loops
So many doc tasks involve interactive decision-making, such as choosing to emphasize a certain detail, validate some other section, or reorganize content for flow—based on emerging information or other dynamic details, that they defy pre-made prompts.
Writers are like a chef in a kitchen tasting the soup and deciding to sprinkle in some spices, then tasting it again and making other ingredient decisions. Needs more salt, sprinkle some in. Re-taste. No, that wasn’t quite what was missing. Maybe a bit of garlic salt? Yes, getting closer. Wait, did we forget the bay leaf? No wonder. Let’s add one in. But wait, we only have half a bay leaf; what can substitute for the other half? Will basil leaves work? Yes, let’s try some. Oh yeah, getting there. Maybe a touch of oregano and we’ll have it! Re-taste? Now how is it?
This is figuratively how many technical writers operate. Complex tasks—those with unclear inputs and outputs, vague owners, or other challenges—constitute the core work many of us do all day as tech writers. We’re not just making words pretty and publishing them.
Example of iterative feedback loops
It’s hard to provide a full example of what I mean without getting detailed and tedious. But to drive this point home, here’s a general representation of a typical interaction for a documentation update I was recently making. (Details are obscured or changed due to confidentiality.)
My main point is to demonstrate how the collaboration with the AI is more than just prompt input. It’s often a process of discovery and realization that surfaces during the conversation. The solution is one we discover together through collaboration rather than produced in a single step from one prompt.
Here’s a general summary of the twists and turns in our conversation. This doc task involves updating a page with info from a similar (but different) API.
Me: “I’m starting to work on adapting this documentation for a new API. Can you help me get started by drafting an initial version based on the provided source text and the new API reference?”
AI: “Certainly. I’ve created an initial draft. I’ve mapped the concepts from the old API to the new one, but I’ve kept the original structure with multiple enum tables for now. I noticed the new API reference is a bit ambiguous about the distinction between these tables. Is that something you’d like to explore?”
Me: “Good catch. Yes, that’s a key point of confusion. Before we dive into that, could you do a quick pass to convert the HTML links to Markdown and just double-check the intro for clarity?”
AI: “No problem. I’ve updated the links and polished the introduction. While reviewing, I also spotted a minor inconsistency in one of the technical sections and corrected it. Now, regarding those tables—I can try to explain the difference based on the context, or I could generate a code sample that might make it clearer.”
Me: “You’re right, I’m still not clear on the distinction between the tables. An example would be great. Can you show me how a value might draw upon entries from both?”
AI: “Here’s a code sample that demonstrates it. As you can see,
valueXuses a type from the first table, whilevalueYcombines types from both. This suggests one table might be for primary types and the other for modifiers.”Me: “That’s a great explanation. It really clarifies things. Let’s incorporate that explanation and the example directly into the docs.”
AI: “I’ve integrated the explanation and the example. As I was doing so, it occurred to me that the document flow might be stronger if we moved this new section up, right after the introduction. What do you think?”
Me: “I agree, that makes sense. Let’s do it.”
AI: “Done. The section has been moved.”
Me: “Hold on, I just got some feedback from the engineering team. It turns out the new API does not distinguish between the values at all. They want us to merge both tables into a single, unified list.”
AI: “That’s a significant change, but it simplifies things. I’ve performed the merge operation. However, I’ve noticed some duplicate values and slight naming variations. How would you like to handle these conflicts?”
Me: “Let’s prioritize the naming from the first table and remove any exact duplicates. Can you handle that?”
AI: “I’ve consolidated the list, removed the duplicates, and standardized the naming as you suggested. The unified table is now ready.”
Me: “Okay, something still feels off. I’m not seeing
someValuein the component as advertised. Could you check the API reference again? Does this object actually provide that enum?”AI: “You’re right to question that. I’ve re-scanned the API reference, and it appears that enum is not available in this object. My apologies for the oversight. I’ve removed the mention of it.”
Me: “Thanks for checking. That clarifies a lot. That probably means we can combine these two sections now, right?”
AI: “Exactly. Since they both refer to the same unified list of types, merging them would be logical. I’ve gone ahead and combined them.”
Me: “This is looking much better. Could you do one last style pass? Check for heading case and other minor errors.”
AI: “I’ve completed the style pass and corrected several heading case inconsistencies. I also converted a few remaining HTML paragraphs to Markdown for consistency.”
Me: “Great. With all these changes, let’s do a final sanity check. Does the document flow logically now? Are there any confusing sentences or awkward phrases that stand out to you?”
AI: “The flow is much stronger. I did find two sentences that could be slightly clearer and have proposed alternative phrasing. I also noticed the word ‘platform’ is used, which our style guide discourages. Shall I change it to ‘service’?”
Me: “Good catch on the style guide point. Yes, please make those final changes.”
This is how many documentation updates tend to go. It’s a back-and-forth conversation, with AI functioning as a conversational agent, a thought partner, and a collaborator.
If your doc queue mostly consists of these issues, the idea of scripting long-running doc prompts seems less likely. This is probably the reason why, despite using AI heavily for 2+ years, I don’t have a prompt library I’m drawing upon. Most of the time, I write custom prompts for the situation at hand.
However, I want to stay open to the idea of long-running prompts for situations that make sense, like the sample tasks I listed earlier. Agentic tools have become quite impressive. When you see an agent running for 5+ minutes working its way through something, it makes me wonder if I’m doing too much up-front steering and handholding and setup.
To this end, I’ve created a prompt to end every conversation. I baked this into my agent markdown file (equivalent to GEMINI.md) to be invoked with the word {{end}}.
Reverse engineering the prompts
When I type {{end}} in a prompt, this means our conversation is over about this topic. When this happens, do the following:
- Look back over the thread and come up with a prompt that can be used for future interactions that have the same intent.
- Then package this prompt into an instruction that can be used with an AI in a future session for a similar task.
However, when I do this after a long conversation, the prompts only confirm my conclusion that most of these collaborative interactions aren’t scriptable as autonomous prompts. Just like a human conversation that has dynamic directions based on feedback coming from both conversation partners, conversations with AI agents have similar dynamic directions.
Additional challenges for long-running agents
Besides the need for iterative decision-making, there are some additional challenges for long-running tasks.

Capabilities available to the tool
Different agents have different tools available to them. For example, can the agent search internal and external content (from intranets and the internet) to gather info, and then parse through that info and use it as input for the next step? Can the tool read bugs—not just the bug description, but bug comments too? Can the agent gather a list of all Google Docs and other assets the bug links to, and bring that context back? If the tool doesn’t have these capabilities, or if you need to grant it permission to run many of these more advanced tools, you might be stuck babysitting the AI through each step of the task.
In my experience, the tools available to an agent are still extremely limited. For example, the ability to read an external URL isn’t usually something they can do, surprisingly.
While it would be nice if agents had many tools at their disposal, there can be risks in giving them too much power. I’d be wary of free-granting an AI permission to read and write external resources, especially outside of a version control system (VCS) that I’m not directly monitoring. It’s one thing to give the tool capabilities to make changes to docs that are in VCS because you can preview and revert any changes before committing them. But if the tool has capabilities outside of VCS (for example, updating Google Docs or bugs or creating changelists), this seems more risky.
For example, one time I asked an agent to create a changelist (CL) and add about 10 people to it, but not to send it yet for review because I was still working on the content. As you can guess, the agent created the CL and immediately sent it out to all 10 people for review. That was the last time I asked it to create a CL for me.
Compounding effects of early errors
Another danger with long-running agents is the compounding effects of early errors. If the task has 15 steps or loops, and early on, the AI makes a mistake in judgment or direction, that error might propagate to all the other turns it makes. By the 15th loop or step, the AI has gone noticeably off course. With a human in the loop providing course correction every step of the way, you ensure more accuracy in that end target. However, if you have to guide AI every step of the way, you lose out on that productivity bump.
It could be that the only feasible long-running tasks are validation tasks—those that check for spelling/grammar errors, broken links, outdated elements, munged formatting, inconsistencies or contradictions, summarization, and more that I listed earlier. They aren’t the type of tasks that require more iterative decisioning throughout.
Conclusion
I find this post reaffirming because if I’m right, if AI tools work as collaboration partners and require a human in the loop, then it’s less likely that humans will be replaced.
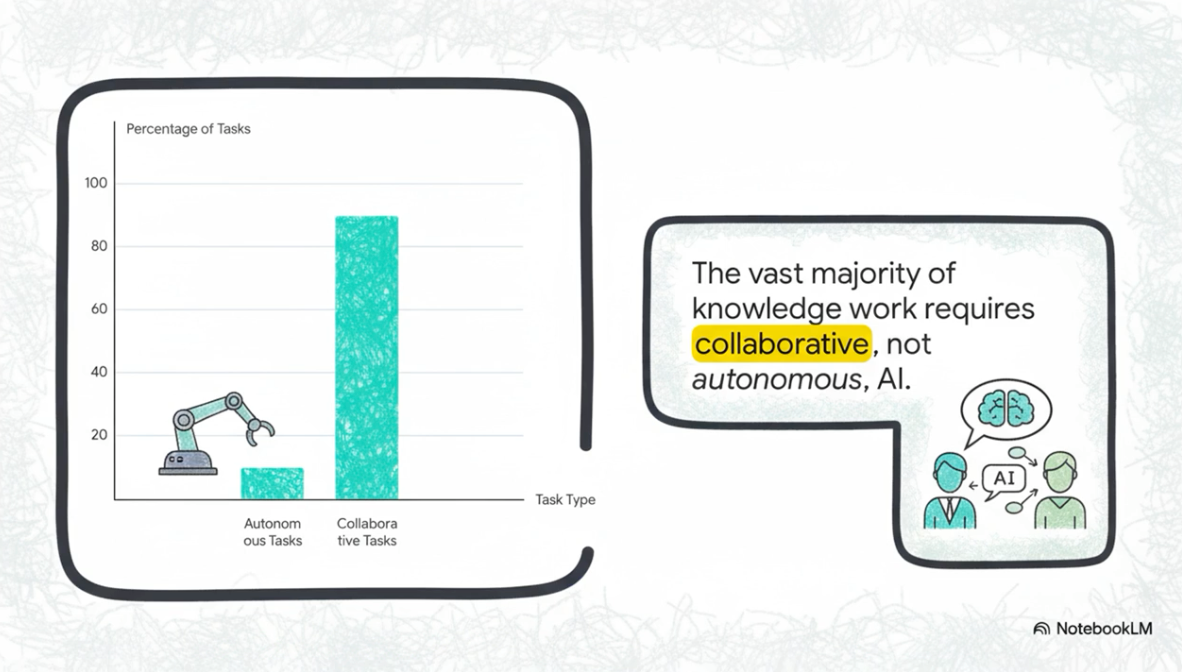
I acknowledge that I’m likely biased and am not eager to see an alternative reality, in which autonomous agents somehow do most of the documentation work on their own. But given that I’m not experiencing this nor hearing any feedback from other tech writers about it, I’m confident that yes, we need a human in the loop collaborating with the AI for the outcomes to be productive. Industry leaders should see AI as collaborative thought partners, not as replacements for humans.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.