

Authoring with Markdown in Jekyll versus Authoring with DITA in OxygenXML
In my previous post, I noted a new series in which I plan to compare Jekyll versus DITA. In this first post, I want to debunk the myth that Markdown formats with static site generators like Jekyll are more limiting than DITA. This is a point discussed in the Content Content podcast that I referenced in the series introduction. This is also a point that I myself was hung up on for a long time.
To an extent, yes, Markdown itself is more limiting than DITA. But Jekyll doesn't just process Markdown on a page -- you can write in Markdown, HTML, Liquid, or JavaScript. With these options, you have a lot of freedom and flexibility -- even more so than DITA.
What is Markdown
Markdown is a lightweight syntax (like a wiki syntax) used for generating HTML. A lot of platforms have Markdown processors (like Redcarpet and Kramdown) that convert the Markdown syntax into the appropriate HTML tags.
Because Markdown isn't standards-based, there are many different flavors or dialects of Markdown. Whereas DITA was agreed upon by a committee and standardized, Markdown was created by John Gruber, a blogger, who wanted a faster way to create HTML.
Since Gruber's release of Markdown, there are at least a dozen different variants of Markdown, usually created when people need some syntax that isn't available in Gruber's initial Markdown. Gruber wanted to keep Markdown simple rather than extending it with more robust syntax.
Although Jekyll processes Markdown, it also processes HTML. You can start a new Markdown file and begin typing in Markdown, and as soon as you run into a situation where Markdown syntax doesn't cover what you're trying to do (for example, figure captions), you can start using HTML. Then when you're done with your HTML syntax, you can switch back to Markdown — all in the same file.
Note that while you can put HTML tags inside of Markdown syntax, you can't put Markdown syntax inside of HTML tags. For example, if you surround a Markdown table with HTML div tags, you must use HTML syntax for the table because it appears inside of the HTML tags.
However, if you don't surround your table with HTML div tags, you can use Markdown syntax for the table, and inside the table, you can use HTML tags (such as to add a span tag to something in your table row, for example).
Note that table syntax isn't in the original Gruber Markdown. It was added by others with later variants. Probably the most common Markdown syntax is Github-flavored Markdown. With Github-flavored Markdown, you can use a syntax for tables, fenced code blocks, and other elements.
When someone says Markdown is too limiting, we really have to extend this to say Markdown + HTML is too limiting, because most processors that process Markdown also process HTML in the same file.
Jekyll and Liquid
Along with Markdown and HTML in pages, Jekyll also processes a templating language called Liquid. Liquid was created by Shopify in part to populate e-commerce sites with product information.
Liquid has common themes from the programming world, such as variables, if-else statements, for loops, and other logic. I'll provide more examples of Liquid in some upcoming posts. But you can use Liquid in a Jekyll page right alongside your Markdown and HTML.
Semantic tagging
One objection is that DITA provides semantic tagging for your content, so you're not just creating div soup, but you actually have semantic meaning associated with the elements.
This may have been more true in the past about HTML, but HTML5 introduces a lot of semantic tags. For example, it provides new elements such as section, summary, and aside. You can leverage all of these tags in your Markdown/HTML pages and Jekyll templates.
XML provides more flexibility with elements, since you can create your own elements and map them to anything you want in your transform stylesheet. Many people say this allows XML to address any potential format that might come along. You just adjust your stylesheet to transform an XML tag into the desired tag for your output, and you're all set.
At first this seems really cool, but I always found that HTML was my primary output. It wasn't very efficient to wrap all my content in a neutral storage container (XML) and then convert all those tags into specific HTML tags. If HTML is the primary output, why not just work directly in HTML syntax?
Except for PDF, most platforms process HTML. Even with PDF, you can use tools such as PrinceXML to convert HTML into PDF using CSS (rather than XSL-FO). You can also convert Markdown into PDF, epub, mobi, and more through gitbook.com.
If you're using DITA primarily to transform content to HTML, the semantic tagging argument begins to feel hollow, because regardless of the semantic nature of the DITA tags, they all get transformed to HTML tags in the HTML output.
If your DITA task contains result and example and postreq and elements, or maybe prereq and context elements, these just get transformed into standard HTML tags, such as p. It depends on how your XSLT stylesheet maps the DITA elements to HTML tags, but at the end of the day, your output will be limited by the tags in the target output.
Although you may have 330 DITA tags, when you push to HTML, your 330 DITA tags become at most 128 HTML tags, because this is how many tags are in HTML. Specialize all you want with your custom semantic tags -- they become p and li and so forth when you output to HTML.
Back when I was using DITA, at some point I realized that steps in task elements and lists in regular topic topics both output to ol and li tags, so I just started using regular topics instead of tasks. And all the deliberation about using info, tutorialinfo, or stepresult after a cmd element in a step becomes pointless when they all transform to p in the HTML output.
Beyond the 128 HTML tags, HTML provides its own method for expansion. You can create custom classes and IDs to your heart's content and define the look and feel of each element however you want.
In DITA, you can add outputclass and id attributes to an element in the same way, but sometimes the Open Toolkit (the code that transforms DITA into various outputs, such as HTML) does some unexpected things with the ID tags. For example, when you add an id tag to a section, the output prepends the topic ID before each section ID.
If the IDs shift in the output, this can complicate JavaScript triggers that depend on specific IDs (such as show/hide tags to collapse or expand section elements).
Element order requirements
Another aspect of DITA authoring is not just elements, but element order. Although you have 330 DITA elements, you can only use the elements in certain orders. For example, a step can only appear inside a task, and so forth.
Although HTML also enforces some order with the elements (for example, an li tag must be used inside an ol or ul tag), DITA takes element order to an entirely new level. Much of the enforced element order is designed to support information typing. Information types are enforced patterns that are designed to fit common information structures.
The enforced element order for DITA restricts the supposed freedom and flexibility of having so many elements available. You may find, after finishing a list, that you actually only have a few options — a result, postreq, or example element.
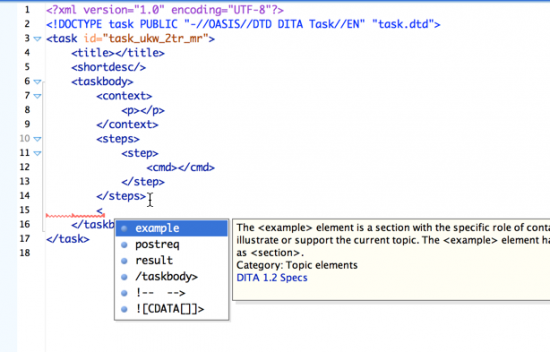
You can extend your options if you specialize, meaning if you extend the DTD schema to introduce your own tag orders and information types. But specialization is a lot of work and most people don't do it. One easy workaround is to use a p or ph tag with an outputclass attribute as a workaround. (This is essentially a lazy way to do divs and spans for custom tags in DITA.)
When I was authoring with DITA, I found the tag orders that enforced information typing to be really restrictive -- I often had to resort to workarounds. For example, you would think you could create subheadings (h3 elements) in DITA without nesting entire concept or task structures inside each other (like Russian dolls), but you can't because the committee that defined the concept information type decided not to allow subheadings except through nested concept elements in the DITA DTD.
Why were subheadings restricted? I think subheading elements were restricted because of DITA's emphasis on extensibility. Theoretically, your information is a bunch of chunks that you can mix and match in any order and arrangement you want.
If you insert a section element, DITA can render it as an h2 or h3 dynamically based on its placement in the DITA map's TOC hierarchy. It can only render it on the fly as h2 or h3 if it is a generic section.
This dynamic heading level rendering is one feature that you can't do in Markdown/HTML when you start using h2 or h3 tags. In Jekyll, if you create a chunk that has an h2 heading, when you include it on a page (using includes), it will always have an h2 heading.
JavaScript
Let's talk about JavaScript (and jQuery) for a moment. Although DITA HTML or webhelp outputs usually use JavaScript, you can't put JavaScript tags directly on a DITA topic. You can only add JavaScript references in your online help plugin's head tags or other help framework files. This means the same script will be available for every page in your output.
This approach leads to slow-loading of web pages. For example, with my previous DITA projects, OxygenXML's webhelp output took a few seconds for each page to load, whereas Jekyll's static site pages usually load in under a second.
But regardless of performance, which can be addressed by the transform plugin, being able to add custom JavaScript on a page can be a huge advantage. Suppose you want a jQuery plugin for a special table on one page (to enable show/hide functionality with data), or you maybe want a shuffle feature, or scrollTo feature, or an accordion FAQ -- there are so many jQuery plugins -- you can do this by adding JavaScript or jQuery directly on your page.
Because you can restrict specific scripts to specific pages rather than adding them to every page on your site, you have a lot more freedom and flexibility to draw upon JavaScript as you design your content. You can leverage dozens of JavaScript libraries without slowing down your overall site.
Additionally, trying to add JavaScript using DITA tags can be a constant guessing game. Suppose you want to use a tooltip that leverages popovers from Bootstrap. Bootstrap requires you to add a data attribute to the element. How do you do that in DITA?
Well, you could add one of the conditional attributes (such as otherprops) to an element, but the otherprops attribute will get dropped in the output. You have to modify the XSLT transform to allow otherprops through to the output, and then you must define the element it becomes — data. You can usually do it, but following all the tutorials online for implementing JavaScript and jQuery plugins get a whole lot more complicated.
Readability
Another factor to consider is authoring readability. With XML tags, it's hard to read the content in a text editor. You can sort of get used to it, but you can't read it so easily unless you have a text editor like OxygenXML to do syntax highlighting.
Here's a sample task using DITA's XML tags:
<task id="task_mhs_zjk_pp">
<title>Printing a page</title>
<taskbody>
<steps>
<stepsection>To print a page:</stepsection>
<step>
<cmd>Go to <menucascade>
<uicontrol>File</uicontrol><uicontrol>Print</uicontrol>
</menucascade></cmd>
</step>
<step>
<cmd>Click the <uicontrol>Print</uicontrol> button.</cmd>
</step>
</steps>
</taskbody>
</task>Here's the same task in Markdown:
## Print a page
1. Go to **File > Print**.
2. Click the **Print** button.Which do you find easier to read? If you said the former, check your pulse -- you may not be human.
With Markdown, you don't have a lot of bulky tags. For example, when you want to mark something as code, you just surround it with backticks, not codeph elements.
With DITA, you'll need an editor such as OxygenXML to make the authoring more practical. This means that everyone working in DITA will likely need some type of XML editor to make the content easier to read and work with.
OxygenXML allows you to make the tags more transparent so they don't get in the way as much. But they're still cumbersome. If you switch to the visual editor, the tags get messy in the code and you periodically have to sort them out. Beyond OxygenXML, there are also MS Word-like solutions that give rich text editor interfaces to DITA content.
With XML authoring, you're inevitably pulled into the vendor world, and you'll need licenses for each of these XML editors, which means the number of people who can author and contribute becomes limited to your number of licenses.
With Markdown, you can send someone a text file, or just tell them to send you a text file, and there's no need for an editor interface to make the content more readable. In fact, I used to do reviews of my Markdown content by pasting them into Google Docs.
Most developers use IDEs when they write code, and you can look at OxygenXML as a kind of IDE for content. But it's nice not to have to rely on the editor in order to work with the content.
Even so, I use an editor called Sublime Text, which costs $70. The Theme - Soda package makes the content very readable, and there are also Markdown packages to provide syntax highlighting. (The number of package options with Sublime are actually pretty amazing.)
Finally, as an author who works with text most of the day, I have to say Markdown is simply more enjoyable to work in. I don't have to exert so much keystroke energy with tags. And because the format is human-readable, I can work in the text mode rather than using an editor that tries to provide a visual rendering.
Live preview
Many editor interfaces try to offer some kind of preview so you can see whether all the tags are going to look good in the output (this is the goal of WYSWIWYG). With DITA, you can periodically build your output at regular intervals and check the content to see how the output looks (after fixing any errors that prevent the build from compiling). But for the most part you only build the content when you're finished writing.
The live preview is where Jekyll hits a home run. When you start a Jekyll project, you're given a link to a web server on your machine where you can view the built site.
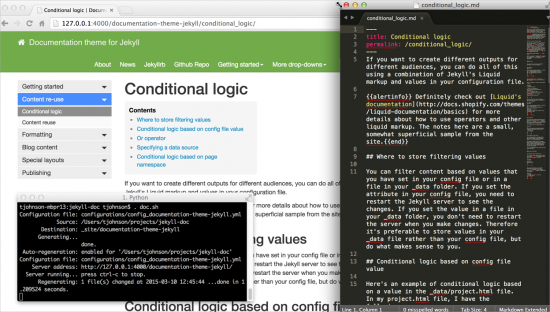
Each time you save content within your project, Jekyll rebuilds the site. It can take anywhere from 1 second to 20 seconds to build the site depending on the amount of content you have, the number of Liquid tags, and other processing needs.
When I'm writing in my text editor, I have a browser open on my second monitor that shows the live preview of the site. Every so often I refresh the page to see the changes. If I ever create content that breaks the build (such as Liquid tags that I don't close), I can see the error message in the iTerm window and fix it immediately.
You can turn the live preview off if you don't want Jekyll to build continuously in the background, but I really like this feature. I actually start builds for each of my outputs. The build process is multi-threaded, so each build can compile simultaneously. I put the different outputs in different browser tabs.
The live preview compensates for any need for a WYSIWYG experience in authoring, because you can see exactly what your content looks like in the browser as it continuously builds.
Conclusion
In conclusion, Jekyll allows you to use all of the following on a page:
- Markdown
- HTML
- Liquid
- JavaScript
Additionally, you don't have to use a special editor to work with the content. You aren't constrained by rigid information types with the tags. And because you're working with HTML and JavaScript, you can do anything that you can do on the web.
When the time comes that a new technology replaces HTML on the web, XML authors will be able to update their stylesheets to map the DITA elements to the new tags. However, there won't be a place to publish the content, because the web, which is mostly built on HTML, won't exist.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.