

Strategies for content re-use in Confluence
I've been knee-deep in Atlassian Confluence lately, analyzing the best way to re-use content. In this post, I'll describe a fictitious scenario that resembles an advanced content re-use situation and then explore various strategies for re-use.
The scenario
Suppose you're creating a bicycle manual for a Trek 7.3 FX (which happens to be the exact bike I recently bought). There's a 7.1 FX and 7.2 FX model for the Trek bike, which you're also creating online manuals for.
Additionally, the parts are also pushed into another brand entirely: Gary Fisher. The parts are mostly the same for the Gary Fisher and Trek bikes, except the parts for the Fisher bikes are rebranded with the Gary Fisher brand. There are three Gary Fisher bike models: City Slicker 2.0, City Slicker 2.1, and City Slicker 2.2. So in total, you have six manuals to produce from roughly the same content.
There are approximately 30 sections in your manual, with topics such as maintaining brakes, adjusting handlebars, tightening bottom brackets, greasing chains, inflating tires, and so on.
There are some variations between the topics, sometimes as trivial as simple name changes, other times more substantial, such as entirely different processes. For example, while the Trek and Fisher bikes both have Shimano brakes and derailers, the Fisher bikes have different cranks and pedals than the Trek cranks and pedals. Both have the same tires and wheels, but the Fisher has a different spoke size. Both have similar seat stems, but the Trek is fastened via a bolt while the Fisher is fastened with quick release, and so on.
Let's say you're using Atlassian Confluence, and you're writing for an online format. What are your options for content re-use? What strategies do you use?
Separate spaces for each version
First, you know that your Trek bike customers won't want to see information about Gary Fisher bicycles in the same manual. While a Trek customer might be okay seeing content for 7.1 FX, 7.2, FX, and 7.3 FX model stuffed into the same manual with various notes calling out different versions, the audience won't tolerate documentation for other brands to also be jammed into this same guide. You also don't want readers to know the parts are the same for both bikes.
One strategy is to create a separate space in Confluence where your source content will live. In this space, you write the source documentation. You then create another space for your Trek content and another space for your Gary Fisher content. You can then push the source content into these other spaces. You keep the source documentation space private.
If there's a lot of variation between the brands, you could even create six separate spaces that you publish to -- a space for each bicycle brand and version.
In Confluence's own documentation, the authors use spaces to accommodate each changing version. They publish the latest version always in the same space, but then archive the previous versions into a space that reflects the version number. The following screenshot shows how each version lives in its own space.
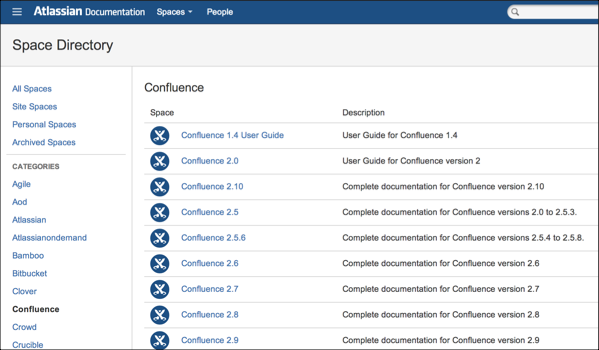
Variant topics
Putting content for different versions into different spaces is one strategy. If a topic on "Adjusting handlebars" is exactly the same, it might fit nicely into all six spaces. But how do you re-use content when only part of the topic is the same?
Let's say the section on brakes has the topic "Maintaining your brakes." The content is 80% the same between all the Trek and Fisher models, but the higher end versions of thee bikes have higher end components, so there's some variation in the help content.
You could create six separate versions of "Maintaining your brakes," but then you'd have 80% redundant content that is copied and pasted between the six topics. How do you re-use part of a topic?
Probably the easiest way is to apply conditional tags on the content. The Scroll Versions plugin is a nifty plugin that you can add to Confluence (though not with the On-Demand version of Confluence). Scroll Versions calls this conditionally processed content a "variant."
Through the conditional content macro (part of Scroll Versions), you can associate content with different variants (Trek 7.1 FX versus Gary Fisher City Slicker 2.0, for example). When you publish the page, you can publish a specific variant of the page to a specific space. In this scenario, the same page might have six different variant outputs; you publish each variant to a different space. It's not too different from the way conditional tags work in Flare or conditional processing in OxygenXML.
Alternatively, rather than publish each variant to a different space, you can just publish the page. When you publish a page that has variants, a small menu appears below the page title that allows the user to select the variant for the page. If you select Trek 7.3 FX, all content that is selected with a different variant gets hidden.
When users navigate to other pages, the same variant will already be selected. (There isn't a way to tie variants to user groups, unfortunately.)
The only problem with this variant menu method is that the drop-down box for selecting variants is pretty subtle. But at least this selector reduces the need to publish the same content to a lot of different spaces. Here's a screenshot from Scroll Versions showing the variant menu displayed on a page. Here you can switch to Mac OSX or Windows Vista.
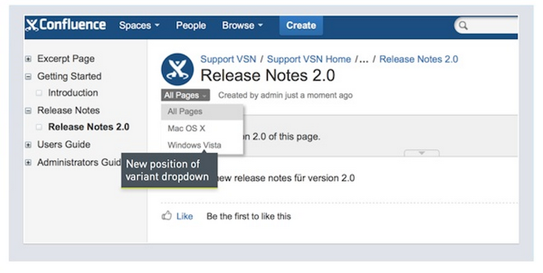
Tab groups
Another strategy would be to not publish different variants, but instead put the differing information onto the same page, organized into local tab groups. Through Confluence's local tab group and local tab macros (available from the Navitabs plugin), you can create tabs on the page that allow users to easily select the version that applies to them.
You see these tab groups a lot when documentation has programming code samples in different languages. Here's an example from Twilio's API doc (which isn't on Confluence but provides a good example of on-page tab navigation).
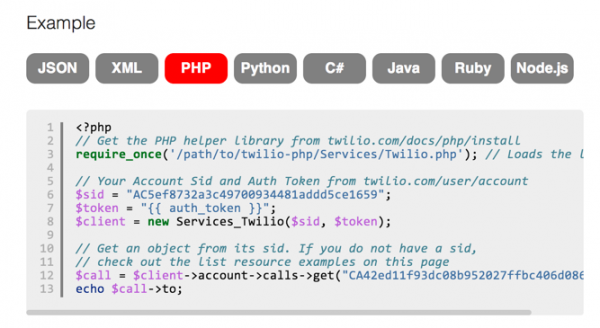
One hassle is that the user must always select the right tab. And in some cases, the differences might be pretty extensive. Usually tabs show small differences in content, not entire pages.
Re-used notes
In some sections, you might have a note that you re-use in a lot of different topics. For example, you might have a note about making sure users don't overtighten the parts as it might lead to stripping the bolts.
If you have the same component that appears in a lot of different topics, you can re-use it through the multiexcerpt include plugin. In your source space, you create a page that contains all of your notes and other frequently re-used tips, cautions, etc. You store each of these notes in a multi-excerpt include macro. You can then use the multi-excerpt page include macro to embed the macro in the topics you want it.
The multi-excerpt macro has some problems, however. The plugin doesn't tell you which pages you've embedded the multi-excerpt content into, so unless you're keeping track of it manually, there's no way to know where all you've included the multi-excerpt macros, not even by searching for the macro code.
Another problem is that Confluence's search results don't index the multi-excerpt macro content. That's right -- all multi-excerpt macro content doesn't appear in search results at all. I'm told that you have to install a separate caching plugin as a workaround.
However, one nice thing about the multi-excerpt plugin is that it's available with Atlassian Confluence On-Demand, whereas the Scroll Versions plugin isn't.
As an alternative to the multi-excerpt include plugin, you can also use the built-in Excerpt Include macro from Confluence, but then you can only include one excerpt per page, so each note would need to live on a separate Confluence page in your source content.
Search results
One problem with putting similar content into separate spaces is handling search results. By publishing to separate spaces, you might assume the reader starts in the right space and then uses a search that restricts results only to that space. But what if the user starts from Google and searches for "maintaining brakes Trek 7." Which page will surface? Or what if the user searches from the master search box in Confluence, which allows searching across all spaces on the site?
Atlassian explains their search weighting here. My guess is that if the keyword matching is the same, the most recently authored pages will outrank other pages, and Google will serve up only that single page from your domain. As such, It might help to add a banner at the top with links to other bike versions, or to even put the version in parentheses in the title (such as "Maintaining your brakes (Trek 7.3FX)."
Honestly, I'm not really sure how search results with similar content play out on a Confluence site. But this is definitely something to keep in mind when you reuse content on the same site.
Authentication
So far I haven't mentioned authentication. I've assumed that all the content should be readily available to anyone searching on the web. With mainstream bikes, it's hard to see why this wouldn't be the case. So let's tweak the scenario a bit. Suppose you're selling software to the NSA. They don't want the help available to anyone on the web, but they still want a web format.
In this case, you could follow the same strategy of publishing content into different spaces, but you would need to tie access to the spaces to specific user groups. You would also need to have someone add users to the right user groups (or connect to an authentication directory like LDAP). And the licensing costs for Confluence would be much higher, since each logged-in user counts against the license.
Unfortunately, it's not possible to tie variants to specific logins (without a custom hack), so users would still need to select their version or model.
How are you re-using content on Confluence? Do you agree with my strategies here?
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.