

Moving from passive to reactive documentation -- recording of presentation by Greg Koberger, ReadMe.com founder
The following is a recording of a presentation about passive versus reactive documentation by Greg Koberger, developer and designer for ReadMe.com, a slick new REST API documentation tool.
Greg gave this presentation at the STC Silicon Valley chapter meeting on January 12, 2015 in Santa Clara, California. (He gave a similar presentation to a Write the Docs meetup group in San Francisco.)
Listen here:



You can view the slides here.

About Greg Koberger
 Gregory Koberger is the founder of ReadMe.com, which provides collaborative developer hubs for companies or projects. He has previously worked at Mozilla, Greylock, and numerous startups. You can learn more about Greg at gkoberger.net.
Gregory Koberger is the founder of ReadMe.com, which provides collaborative developer hubs for companies or projects. He has previously worked at Mozilla, Greylock, and numerous startups. You can learn more about Greg at gkoberger.net.
You can explore ReadMe.com here:

Here's my brief summary of the presentation.
Overview of doc levels
Greg outlined three levels of documentation:
- Passive: Has no knowledge of the user.
- Reactive: Responds to an action from the user, such as something the user says or does.
- Proactive: Anticipates the user's needs and pushes the appropriate content to the user at the right time.
Passive
Passive documentation is documentation that could be contained inside a book. It is often produced by static site generators, and includes deliverables such as topical guides, tutorials, and reference material.
Level 1.5: Passive(ish) example
Moving a half a step beyond passive, examples such as forums, Q&A sites like Stack Overflow, and other community driven or collaboratively edited sites aren't totally passive, nor do they have completely static content. With a Q&A post on StackOverflow, for example, users are asking questions and getting responses from other users.
(Greg noted that StackOverflow provides a compelling model for documentation. If someone searches for a technical answer and can't find it online, he or she asks the question so that the next time someone searches for the answer, it's available.)
Why do docs need to be dynamic?
Greg said that when you're building a website, on average a developer uses between 8-10 APIs. As a result, developers need to quickly get in and out of various documentation sites, finding code snippets to easily copy and paste, locating quick answers, etc. When people are traversing so many different APIs, they don't have time to read through tomes of documentation at a leisurely pace.
Dynamic docs can help reduce the cognitive load on the user who is quickly looking for answers and code samples.
One example is a section on authentication. Nearly every API doc includes this section, with a sample about how to pass your credentials or API token with REST calls. Why not have the user log in to the doc site, and then auto-populate code samples with his or her authentication credentials directly into the code samples dynamically, making it easier for the user to copy and paste the sample? This is one example of how to reduce cognitive load on the user.
Level 2: Reactive doc
With reactive documentation, you use what you know about your users to make their lives easier. Ideally, code samples and other information should be personalized with information pulled from the user's profile.
For example, if you know what platform the user is on (based on profile information), you can dynamically filter the doc content. If the user's preferred language is PHP, your code snippets can default to the PHP tab instead of the Ruby tab, for example. Greg emphasized that code samples should be copy-and-pastable so they just work.
Another example with reactive documentation might be an on-boarding tutorial. If you know details about the employee's location, role, and other details, then you can dynamically filter the on-boarding tasks to fit that profile.
Error messages are another place to personalize and customize content. The errors themselves can contain variables that are personalized -- for example, instead of "Failed to instantiate module," if your company was ACME, the error message might say, "Failed to instantiate your ACME module." Error messages should also include links to relevant sections in the doc.
Another example of reactive documentation is with Stripe's API doc. The API responses (which appear in the right column) are based on your own data. How? To use the Stripe API you must create an application key of some kind. To create this key, you must log in. Therefore when you're logged in, Stripe knows your application key. The API code samples can pass in your authentication key and return your specific data for each of the endpoints.
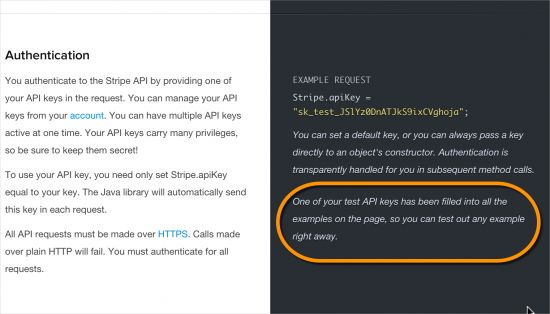
This personalized approach to documentation can make the code samples and information more real, immediate, and understandable. It's one way of further reducing the cognitive strain on your users.
(If you're not logged in to the site, you'll see generic responses.)
Level 3: Proactive documentation
The final level of documentation is proactive. Proactive documentation reaches out to the user before there's a problem. For example, suppose there's an update with an endpoint in the API. When you code your application, perhaps a special function detects that you're using this updated or deprecated endpoint and sends you a special warning message.
Or perhaps other elements in your code trigger certain documentation responses. For example, suppose your code is not set up to make very efficient calls (e.g., maybe you're iterating through an array and calling all the values each time in an unnecessary way). The documentation could detect inefficient code and point you to a tutorial to show you best practices.
Readme.com
If you do REST API documentation, definitely check out ReadMe.com. With recent funding from Y Combinator for this startup, Greg is focusing heavily on developing readme.com with more robust features. (Even so, I think it's a pretty amazing platform as is.)
If you're doing REST APIs for an online audience, this platform will make your life easy. You can [eventually] integrate information about your API so that your documentation takes on some of the reactive qualities that Greg talked about.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.