

What Does Content Re-Use Look Like in a Web CMS?
One challenge I've recently been considering is how to handle content re-use on a web content management system, such as Drupal, Joomla, WordPress, or some other web platform. Let's say you're writing about ACME widgets and have three different audiences: ACME developers, ACME sales people, and ACME administrators. All your help content is hosted on the same web platform.
In this scenario, you have a lot of different information, much of it overlapping. For example, with your ACME widgets, you have some conceptual info, some strategic info, some configuration info, some management info, some API info, and some server info -- all related to the ACME widgets.
The sales people need the conceptual and strategic info but don't want to be burdened by the configuration, management, API, or server info.
The developers mostly need the API info and server info, though they do need some light familiarity with the conceptual info as well. They don't need the strategic info since the developers implement the spec from another team that formulates the strategy.
The administrators need the configuration and management info but not a whole lot of other info.
If you were working in a help authoring tool (HAT) or another model, you could create all your content as standalone topics and then produce three distinct outputs -- one for each audience. Your developer guide could include the API and server info while providing light conceptual topics as well. Your sales guide could walk through the conceptual and strategic components while omitting the more technical content of the other guides, and so on.
The model of distinct outputs for distinct audiences is a model many technical writers are familiar with. It works because the information sets are walled off from each other in clearly separable ways -- the help for the developer opens in its own web view and navigation. Search results are restricted to that web help file only.
But rather than publishing independent, standalone outputs, in this scenario you're using a web platform for all your help content. It would be odd to have multiple instances of the web platform. For example, you wouldn't have one Drupal instance for developers, one Drupal instance for salespeople, and one Drupal instance for administrators. You could technically do it, of course, but managing all those separate web platforms would be a headache. Instead, you have one web platform for all your content.
How do you re-use content intelligently on the same web CMS platform?
Approach 1: Push the same topic out to different TOCs.
You could store the topics in a re-usable format outside the web platform and then push out the topics multiple times, sometimes including the topic in the information's table of contents (TOC) and sometimes not.
However, having multiple versions of the same topic appear in different places on the same site gets confusing. Your search results would show redundant instances of the same topic, and the overall content on your site would perhaps double or triple in size. The user browsing around the various pages would see a lot more content, much of it the same but repeated. So this approach seems odd and inefficient.
Approach 2: Pull the same topic into different TOCs.
You could write each topic as its own article and then pull the same topic into different content TOCs. For example, if you have a "Configuring Widgets" topic relevant to both administrators and developers, you could create one article about Configuring Widgets and put the same topic in both TOCs -- in both the TOC for developers and the TOC for administrators.
The question is what TOC shows when you view the topic? You can't have multiple TOCs appear, so viewing the topic would potentially decontextualize the user from the TOC he or she was previously navigating.
Approach 3: Create tag-based views of topics.
You could create each topic as its own article but tag the content with keywords such as configuration, sales, API, management, and so on. Users could navigate by tag and see all the topic results that have that tag. Clicking on the "ACME widget development" tag might include the server, API, and configuration topics. Even more granular tags inside of these tag buckets could allow users to further filter the information they see.
Although the same topic might include multiple tags and so appear in multiple views, this filtering of content is more familiar to readers as they would probably know that one topic can have more than one tag.
The problem with a tag-based navigation is that you lose the hierarchy of a TOC. All files become a flat, unordered list of topics. The lack of hierarchy makes it more difficult to understand the meaning and structure of the information at a glance.
Approach 4: Abandon the TOC, provide search only.
In this approach, you pretty much abandon the TOC and instead provide a search field only. Vimeo's help looks like this. The search provides instant results that take you to a specific topic, but the topics aren't organized into different navigation TOCs and such. The book paradigm seems far left behind here.
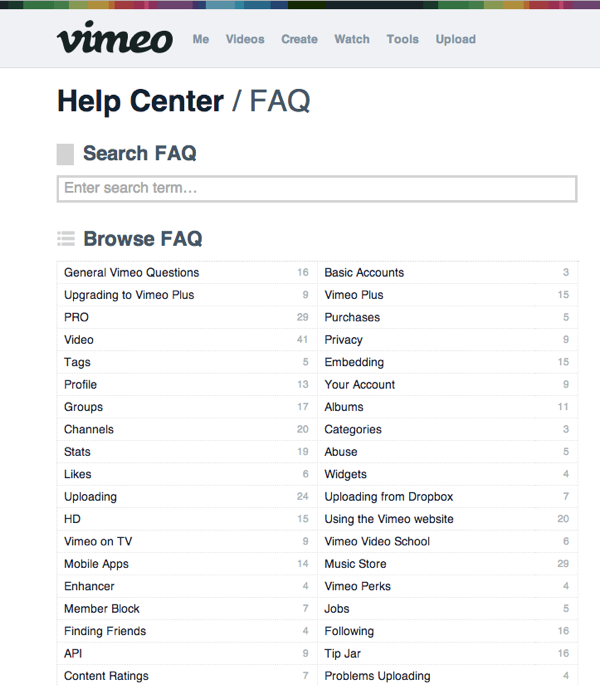
The problem is that users can find only what they know to find. The search helps answer a question but not teach users what's possible. There isn't a logical path through the content to help users learn a new system. Instead, there are lots of disconnected, floating answers. There's no clear progression to follow through the content, so it gets tiring.
Conclusion
Which approach do you use? I'm not sure, but here's my point: On the web, the traditional paradigm of navigation via a table of contents breaks down. So do traditional tech comm patterns for content re-use. We have to consider new paradigms for how we organize content when we put all content on the same web platform. Companies that try to impose the book paradigm into the web end up with a content mess.
What do you think? What approach would you use?
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.