

Collecting feedback post-release
Although you already reviewed some of your docs prior to release with internal stakeholders, after you publish the content you now need to pivot to collecting feedback from external users post-release across your entire landscape of docs. Collecting feedback post-release involves a host of new challenges and processes that I haven’t yet covered, such as how to optimize your feedback form, how to account for random externally driven requests across your dev portal, how to process the feedback from incoming requests, and so on.
- What’s different about collecting feedback post-release
- Location/placement of the feedback form
- Requirements to submit text
- Workarounds for obfuscated http referrer values in Chrome
- Qualitative versus quantitative feedback
- What questions to ask
- Process for handling feedback
- Conclusion
What’s different about collecting feedback post-release
When you’re working on documentation prior to release, you have the full attention of the product team for reviewing and approving the docs. You have a group of product managers, engineers, and others at your present disposal. But when you receive feedback on docs post-release, that same group of people might no longer be present, or they might be hard to locate, especially if you’re updating docs you didn’t work on. You might have to assess feedback on products you know next to nothing about and reach out to people you’ve never interacted with before.
When working with post-release feedback, you also have the challenge of sifting through feedback from people who might not even be your target audience. The feedback might be from customers rather than developers, for example. Or the feedback might be from people looking for a support lifeline when other channels fail them. Or it might just be spam.
Finally, there’s no built-in bandwidth to handle tasks like this, so you’ll likely have to deal with these random requests on top of a full project load. Because of all these factors, handling feedback post-release presents many new challenges.
Location/placement of the feedback form
Let’s start by talking about the feedback form’s design — after all, without a good feedback form, you won’t have any comments to deal with at all (which might be a strategy). There are many different approaches to designing your form, some better than others. In general, most web articles typically have a comment form below the content, particularly with web content. Readers are used to scrolling to the bottom of a web page and finding a feedback form. You’ll have the most success with your feedback form if you follow this general web pattern for providing feedback.
You might be tempted to put your feedback form as a floating button on the side of your docs. Here’s a sample with the feedback button on the side:
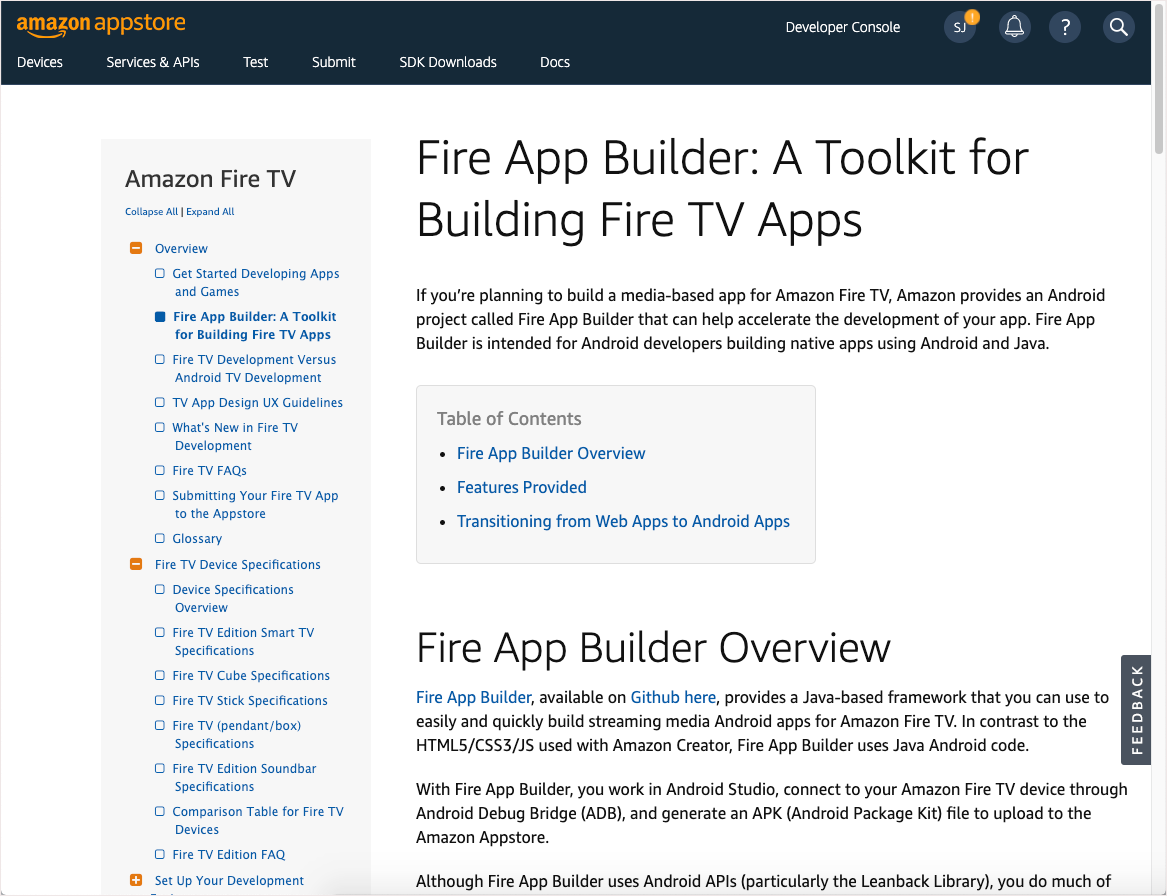
Although this side position is becoming more common, in tests that I’ve done, most people don’t see the feedback button on the side. The feedback form at the bottom was used much more than the feedback button on the side (a ratio of 100:1 or so).
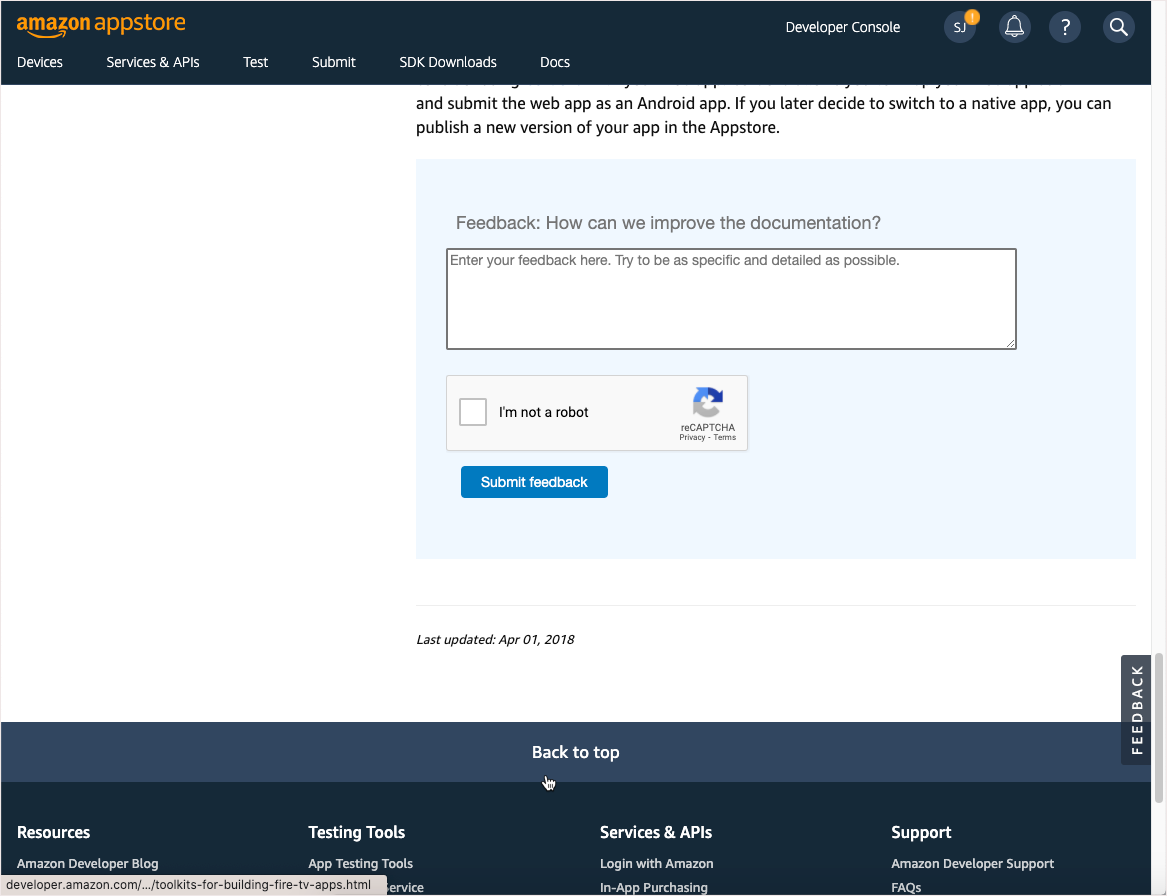
Again, follow standard web practices for placement of common elements.
Requirements to submit text
In addition to putting your feedback form in a highly visible place, if you can lower the friction required for users to enter and submit feedback, you’ll get more feedback. If your feedback form requires developers to log in, or to proceed through a series of authentication screens, or do anything else requiring more than 5-10 seconds of their time, your engagement rate will go down.
The problem with reducing friction, however, is that the easier you make it to enter comments, the more spam you get. Without any spam prevention controls, you’ll be overrun with spam comments in a short time. Try to find a good balance between controls that prevent spam but which don’t challenge users too much. For example, you could implement reCAPTCHA or require some form of login (e.g., login with Google, GitHub, or Twitter), or require users to complete some special task to weed out bots. (Whatever you do, spam will usually find a way to slip through.)
Finally, in order for feedback to be actionable, it needs to be detailed. Consider adding minimum character requirements to the form and encourage users to be as specific and detailed as possible with their feedback. Users rarely want to sink energy into completing a feedback form with no guarantee that the form will go to a human and be read, but a quick one-liner from a user is rarely helpful enough to take any intelligent action on. You might require that the form has at least 100 characters of content to be valid.
You can also choose to show the comments submitted on the article (rather than just collecting the feedback). If you show the comments, and then actually respond to them, it can increase the sense of trust from users to enter their feedback (knowing that the comment will be publicly visible and responded to). However, managing comments places more of a support drain on your team and potentially redirects users away from better support forums and tools, so most doc teams avoid engaging in interactive comments like this. I agree with routing users to support for help.
Workarounds for obfuscated http referrer values in Chrome
One new challenge to collecting feedback in 2020 is getting around the http referrer obfuscation. When you collect feedback, you typically want to know the page that users were on when they clicked the feedback form so that you can make sense of the comments. For example, if the only text users write is “This page needs more examples” or “There’s an error in the code sample here,” unless you know the specific page, it will be difficult to take any action on the feedback. Especially given how brief the comments usually are, you need more context to make sense of the incoming information.
Unfortunately, more restrictive data privacy rules in Chrome now obfuscate the path from the http referrer, showing only the domain. For example, if you submitted feedback from this page, Chrome would show the referrer only as https://idratherbewriting.com, not https://idratherbewriting.com/learnapidoc/docapis_collecting_feedback_post_release.html. This new policy went into effect in October 2020, so if you’re analyzing your feedback metrics and wondering why http referrer shows only the domain, recognize that it’s not due to VPN or incognito modes in browsers but rather due to the new Chrome data privacy policies in place. (Other browsers haven’t necessarily followed suit yet here.)
Depending on your feedback tool, you might need to implement a creative workaround. For example, in Qualtrics (which is a survey tool rather than a proper website feedback tool), you can add custom JavaScript to your form. For example, you could use this script from Stack Overflow that gets the query string from the URL using JavaScript and include that in the form submission. The logic looks like this:
Qualtrics.SurveyEngine.addOnload(function()
{
var getUrlParameter = function getUrlParameter(sParam) {
var sPageURL = window.location.search.substring(1),
sURLVariables = sPageURL.split('&'),
sParameterName,
i;
for (i = 0; i < sURLVariables.length; i++) {
sParameterName = sURLVariables[i].split('=');
if (sParameterName[0] === sParam) {
return sParameterName[1] === undefined ? true : decodeURIComponent(sParameterName[1]);
}
}
};
var docPage = getUrlParameter('page');
var formLocation = getUrlParameter('location');
jQuery('#page').val(docPage);
jQuery('#feedbackLocation').val(docPage);
});
This script assumes that the feedback URL has query strings added, such as https://idratherbewriting.com/learnapidoc/docapis_collecting_feedback_post_release.html?page=docapis_collecting_feedback_post_release&location=bottom. The script parses the query strings from the url and then sets variables docPage and formLocation for each query string. Then jQuery is used to assign those values to unique form elements on the page. You could also add CSS that hides these element where the values get assigned.
(Yes, this is a hack, but if you need to workaround the http referrer restrictions, a technique like this might be necessary.)
Qualitative versus quantitative feedback
Another aspect of the feedback form is whether to solicit qualitative or quantitative feedback, or both. Qualitative feedback refers to free-form, descriptive text whereas quantitative refers to multiple choice options (or similar). Although the idea of multiple choice options seems appealing, as it would allow you to create metrics around the content (e.g., rate the docs based on clarity, accuracy, relevance), quantitative data is actually rarely helpful. If a user ranks the doc low on clarity or relevance but doesn’t add clarifying information, this makes the feedback hard to decipher and take any action on. Additionally, you’ll have to sift through spam bot submitted forms versus forms from actual humans. Every time I’ve incorporated quantitative options into feedback forms, the results have been useless.
What questions to ask
Your feedback form can be as simple as asking one qualitative question:
How can we improve the documentation?
Remember, people usually give 30 seconds or less of time in providing feedback. If you try to add a lot of questions, they should be specific to the information on the page, not general task-analysis questions.
I also recommend adding some placeholder text that encourages users to be descriptive, such as “Enter your feedback here. Try to be as specific and detailed as possible. At least 100 characters (several sentences) are required.” For example, like the following screenshot:
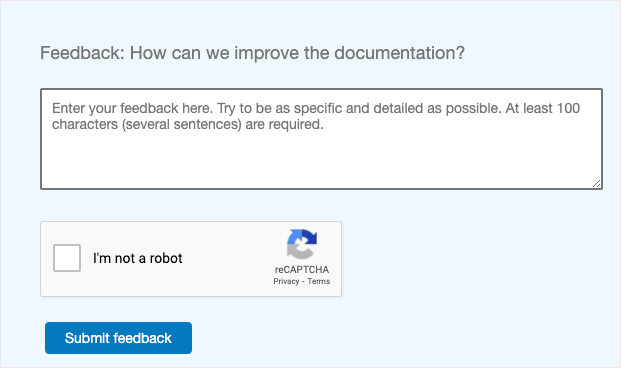
If you need metrics around feedback, you could quantify the number of comments received for each doc set, and then indicate what actions were taken. What percentage of the feedback was actionable, and how many tickets did you close related to doc feedback, etc.? How many tickets were from humans versus bots?
Process for handling feedback
Just collecting feedback is only the first step. The next step is to implement a process for sorting, assessing, and taking action on the feedback that comes in. This might sound easy but can be especially challenging if no one is asking you to take action on this feedback. Product teams usually submit requests to doc teams for upcoming features and releases; they are often quiet when it comes to documentation for existing features. Taking action on incoming feedback is almost like an extracurricular task.
A process for handling incoming feedback could look like this:
-
Every time you do sprint planning (e.g., every two weeks), look through the feedback you’ve received and identify any feedback that is detailed and actionable. Create tickets for each of these actionable items.
-
Decide which tickets you want to work on for the sprint (e.g., due to priority, ease of handling, or other reasons) and assign the tickets to the sprint during your sprint planning.
Given that these tickets will rarely be a priority, to avoid neglecting and forgetting them, consider making it a requirement that each team member takes on at least one documentation feedback ticket per sprint.
-
Reach out to product teams to keep them aware of the incoming tickets. The product owner should be Cc’d as a watcher on the ticket so they are aware of what’s going on with the user experience of their product.
Product teams rely on various teams (documentation, support, field engineers, developer advocates, etc.) to gather feedback about their product. Especially if you see trending issues related to specific pages, try to identify what might be driving the issue and escalate this to the product owner.
To allow contact for docs across your portal, it’s a good idea to maintain a list of contact points that identify at least one product owner per doc set. It’s even better if you can identify the team that owns the product and any ticket assignment categories for the team.
Conclusion
Although collecting doc feedback post release is important, most feedback I’ve seen in comments rarely goes beyond identifying simple issues. Most users submit feedback to let you know about broken links, typos, broken code samples, or other obvious issues. You won’t get the detailed, substantive feedback from doc reviews that you do as part of pre-release review process from internal product teams and stakeholders. The best time to review your docs is before release, not after. The feedback you collect post-release can help catch errors and other problems, though, and so shouldn’t be avoided. This feedback can also help you funnel insights from customers back to product teams, which helps increase your value to the organization.
About Tom Johnson

I'm an API technical writer based in the Seattle area. On this blog, I write about topics related to technical writing and communication — such as software documentation, API documentation, AI, information architecture, content strategy, writing processes, plain language, tech comm careers, and more. Check out my API documentation course if you're looking for more info about documenting APIs. Or see my posts on AI and AI course section for more on the latest in AI and tech comm.
If you're a technical writer and want to keep on top of the latest trends in the tech comm, be sure to subscribe to email updates below. You can also learn more about me or contact me. Finally, note that the opinions I express on my blog are my own points of view, not that of my employer.
142/168 pages complete. Only 26 more pages to go.